What if you could hydrate billions of rows per minute from a data lake, as needed, into a powerful, flexible high-performance analytics speed layer?
Hadoop and cloud-based object stores (such as S3 and ADLS) have become the de facto stores for the vast volumes of data generated by modern business. Query frameworks such as Hive, Impala, and Presto have made it easier to query this data using SQL. But these tools typically suffer from a shortage of compute cycles, are slow, and better suited to batch workloads. They do not work well for use cases where interactive 'what-if' analysis is required.
Kinetica, as an in-memory, GPU-accelerated analytics database, is ideal for this sort of interactive analytics, but memory resources typically limit this to the terabyte scale. What if it were possible to quickly move large subsets of data from storage into Kinetica for high-speed query, and then dump it for another set, as needed?
For example, a retailer may have petabytes of customer behavior data sitting in Hadoop. They might want to plan store layouts and product assortments based on past trends for regional markets. Rather than deal with slow queries, they could hoist the data for the Houston market into Kinetica, work with it interactively, and then switch over to data for store layouts from the Los Angeles market.
Folks that are used to traditional legacy bulk loaders or ETL tools might assume that it takes so much time to move data in and out that the benefits wouldn't be worthwhile. However, Kinetica's ability to distribute ingest across multiple nodes, and reduced reliance on indexing, makes loading terabytes of data simple and fast.
How fast?
Blazing fast.
In a recent implementation of Kinetica with the new Spark Connector, a 10-node Kinetica cluster was able to ingest 4 billion ORC records per minute (14 columns per record) from a Kerberized Hadoop cluster. Each Kinetica machine was equipped with 4 P100s per node and effectively saturated the network capabilities of the hardware.
Let's dive into how this works:
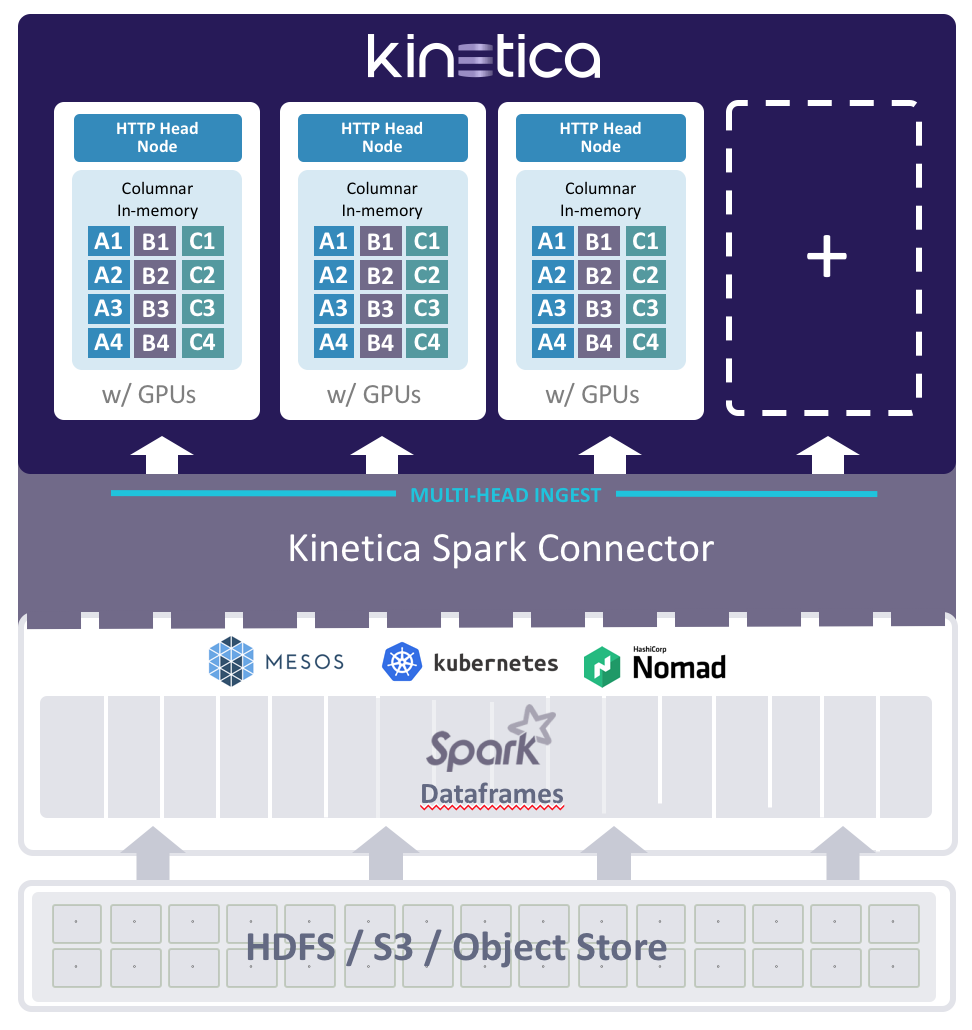
Multi-head Ingest with Spark
Kinetica treats every GPU as a logical node. So a machine equipped with 2 P100/V100 GPU cards is treated as 2 nodes. The Kinetica Bulk Inserter (an API for bulk loading of data) is intelligent enough to recognize that there are two nodes and performs ingest to both the nodes in a massively parallel fashion! The more GPUs and machines you have, the more parallel and faster your ingestion process is going to be.
In addition, the Kinetica Spark Connector speeds up the ingest process even further. Each Spark DataFrame can be comprised of one to many partitions. Each partition invokes the Kinetica Bulk Inserter, so if a DataFrame has 100 partitions, each of them can invoke the Kinetica Bulk Inserter, resulting in 100 processes moving data into Kinetica. This is what gives it the parallelism and the power to move data from Spark to Kinetica in a rapid fashion. You can also dedicate the number of executors to the Spark Connector for speed and parallelism as needed.
The following serves as an architecture:
The workflow can be explained in the following steps:
- Data is collected and stored in Hadoop. These datasets can be in AVRO, Parquet, ORC, or even plain ASCII/binary formats.
-
As Spark is now the de facto data processing mechanism for Hadoop, a Spark DataFrame can be
leveraged over any of these files. For example, if the source files are stored in an ORC format,
creating a DataFrame is as simple as executing the command –
val df = spark.read.orc("path to orc file"). This DataFrame takes care of deserializing any format to plain text. - Each DataFrame can also be configured with partitions. The desired number of partitions is dependent on the volume of data and the amount of parallelism required to process this data.
- The DataFrame can be configured to name each field logically (if not already done). The names, along with the datatype and size for each field of the DataFrame, are used to automatically define the target table in Kinetica (DDL). So one does not need to worry about setting the names and datatypes for each column in Kinetica.
- From within Spark, the target table in Kinetica can be configured to either be sharded or replicated. It can also be configured to have a Primary Key and Shard Key. Each of the columns in the target table can also be compressed using Snappy, LZ4, or LZ4HC, so there is a lot of versatility when using Kinetica's Spark Connector.
- Once all the desired features are set, all that needs to be done is call the Kinetica Loader from within the Spark shell and the tables automatically appear in Kinetica.
Watch this video for more details about the Kinetica Spark Connector:
Summary
The high-speed ingest capabilities of Kinetica with Spark provide a new and highly efficient framework for high-speed interactive analytics on petabyte-scale datasets. The approach is far simpler than the multiple layers found in a Lambda architecture, and Kinetica's similarities to relational databases provide both power and ease-of-use for developers, analysts, and admins alike.
Downstream applications can connect to Kinetica via APIs (available as REST or in other language bindings), SQL (JDBC/ODBC clients like Tableau), or via WMS (like ESRI, etc.) and consume content. You can also use additional techniques such as building projections to further enhance performance within Kinetica.
Kinetica is now available with a Trial Edition so you can try it out yourself. Or Request a Demo, and we'll have a solution engineer walk you through it in more detail.