Joe is a member at a retail discount chain. Membership gets him significant discounts on all sorts of products from tires to televisions to the cheap cup of coffee he picks up daily on his way in to work. The only problem for Joe is that every time he orders a coffee, the cashier asks if he is ready to renew his membership for another year. This happens every single time.
The retailer is of course trying to retain members, and the best time to get someone to renew is at the checkout. But how can the store prompt Joe, who visits a couple times a week, differently than other customers, who might only visit once every couple months?
These are the sorts of challenges that are facing data scientists in retail today. And this is where artificial intelligence is being put to work to facilitate better interactions with customers. Smart systems predict what products a customer might like, provide better targeting of advertising, and flag when the best time is to prompt a customer to renew a membership.
But assembling these systems can be highly complex. Transferring large volumes of data between operational systems and data science tools is costly in terms of both time and skills. And the stack of technologies and tools can be convoluted, requiring many different skills to master.
Kinetica is able to significantly simplify and speed up the operationalization of AI workloads. It brings together the familiarity of a relational database with the capabilities of a data science platform. Recently, we had the opportunity to put this to work with one of the largest retailers in the world.
Prepare Data with SQL
There is no shortage of popular machine learning and data science libraries available in Python for working with historical and live data to build recommendations and predictions. However, before any of that happens, data must be pre-processed, manipulated, and massaged into the needed structure. This data preparation phase can often be 70-80% of the work in any given project.
In this particular case, transaction historicals were spread across HDFS, a transactional database, and Cassandra. However, pre-processing with MapReduce, HiveQL, and Spark were cumbersome, slow, and costly tools for doing this.
In contrast, Kinetica can be used like a familiar RDBMS with interactions in SQL. Data scientists are able to be more productive working in SQL, which is easier, more pervasive, and more expressive than other more cumbersome tools. This made it quicker to transform the data into the right frames with UNIONs, JOINs, GROUP-BYs, and other relational algebra.
In-memory, and Designed to Use GPUs
Kinetica is built from the ground up to leverage GPUs for data processing. When building out an operator graph for a query, the internals automatically know what to send to the GPU and what to run on a CPU. When working with data on multiple GPU cards, across multiple nodes, Kinetica automatically distributes the workload for maximum effectiveness. It is an easy and highly efficient way to work with large volumes of data.
On this particular project, model pre-processing had been done with Spark, HiveQL, and Teradata. Simply processing the data was taking hours. Kinetica was able to do the same task in just minutes.
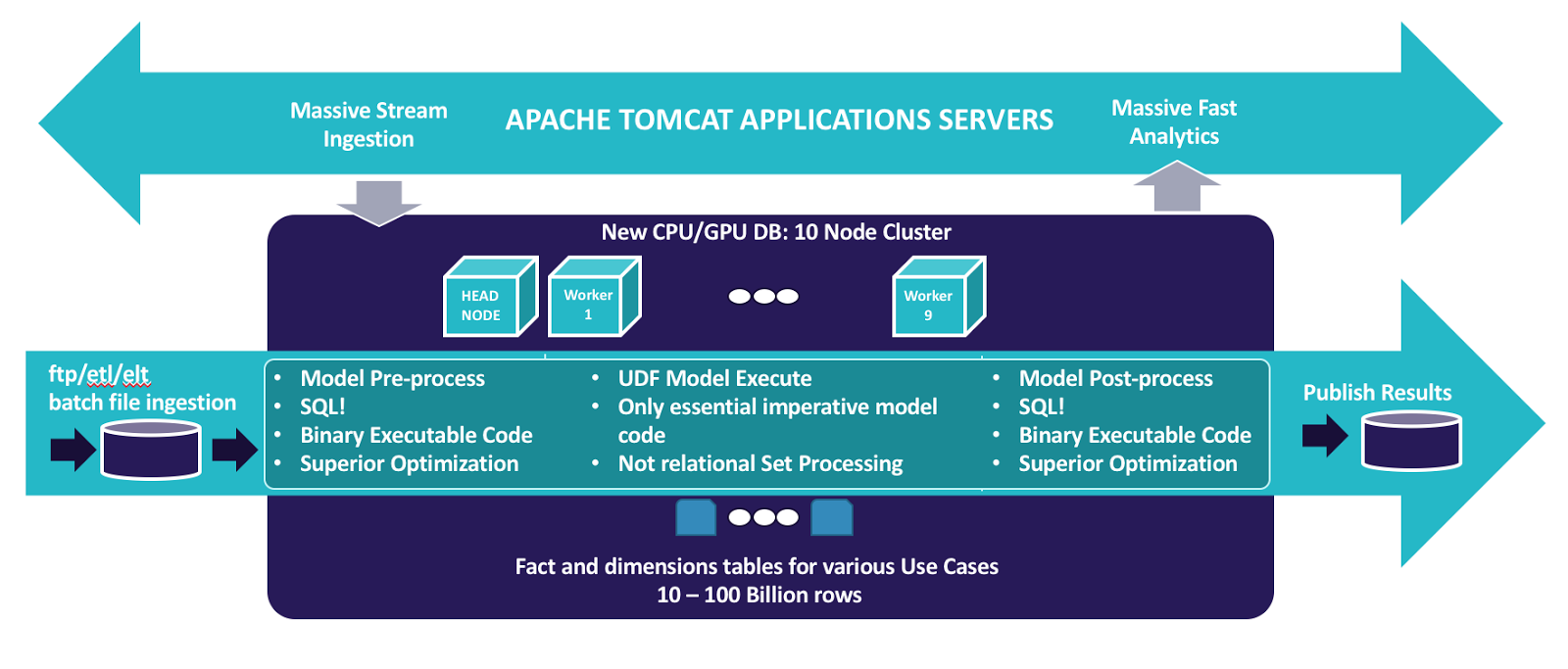
The user-defined functions (UDF) framework in Kinetica makes it possible to run custom Python or Java code directly on the data, within the database. In this project, non-parametric models were used to predict the likelihood of another visit before the customer’s membership expires. But the UDF framework can also work with popular machine learning frameworks such as Tensorflow and Torch.
It’s much easier to bring the model to the data, versus moving the data to the model. While the actual models might run the same speed on Kinetica as a standalone GPU farm, the time savings in preparing and not having to move the data can be immense. When you’re working with billions or trillions of rows, moving data between systems creates a ceiling on the services you can provide.
Fast Ingest
For membership renewals, the system had the luxury of ingesting and processing the data daily. The model, embedded as a UDF, would be run every night and the output written to a table to be sent downstream to stores. However, many AI use cases require the use of live data.
For this client, they also used Kinetica to monitor stock replenishment. Every transaction was logged against stock counts to identify where and when stock needed to be updated. Kinetica is designed to spread ingestion of data across multiple nodes without relying on a single head node. And because there is reduced reliance on indexing, that data is available for query the moment it arrives,
In this case, with stock data streaming in, and 600 to 1200 queries per second, Kinetica was able to rebuild intermediate aggregation tables in just 10 seconds as opposed to the hours it had taken previously.
That’s hours to seconds.
This is a great example of how Kinetica can be used as high-throughput analytics layer, working with large volumes of streaming data, concurrent usage, and on business-critical workloads. Kinetica is able to handle a variety of workloads while being bombed with feeds from Kafka, Flume, and Storm. It offers the throughput you might expect from key-value databases, but in an analytics layer.
Summary
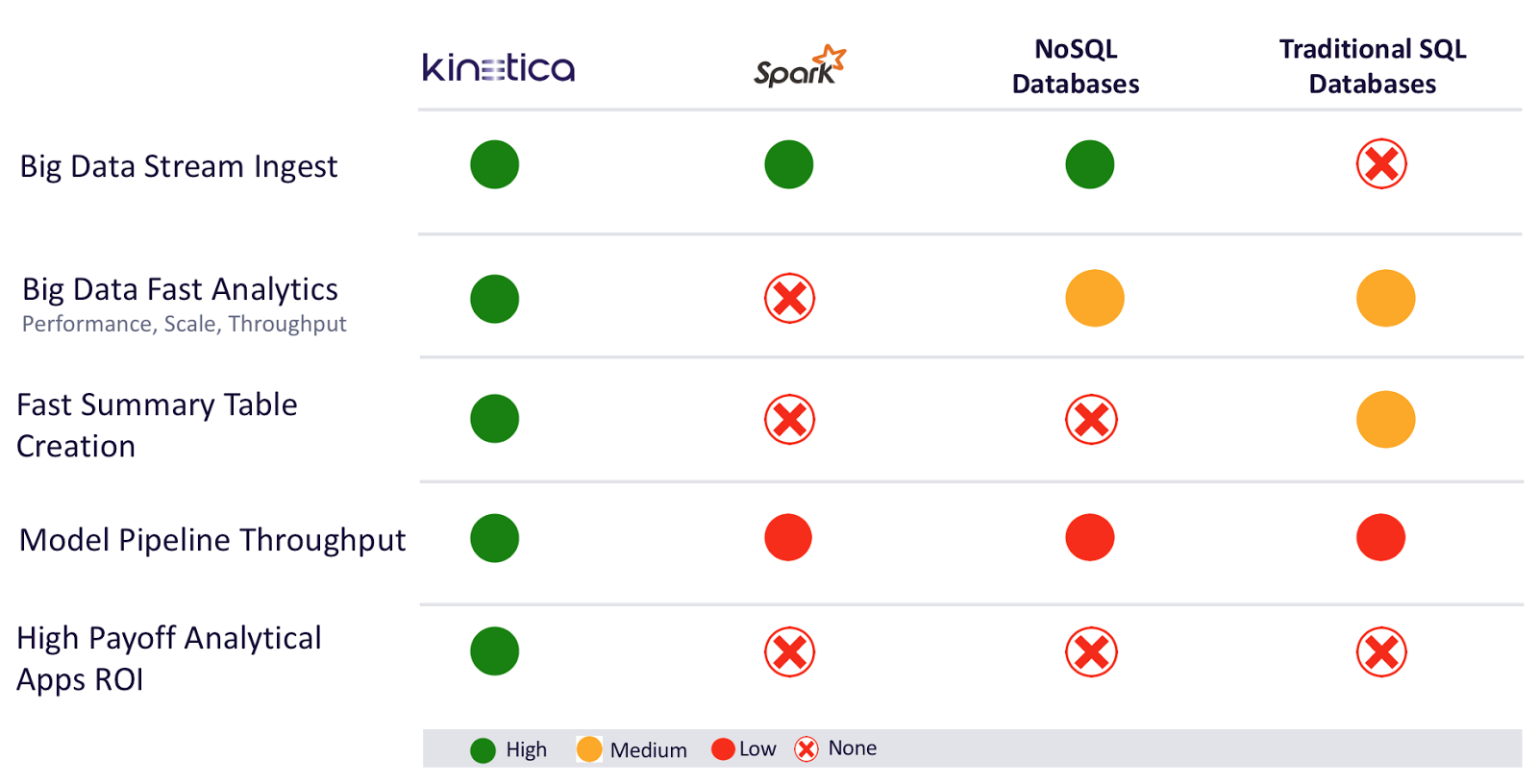
For this customer, Kinetica was able to bring the benefits of multiple systems together into a single stack. A single system that could do more with less hardware. Kinetica had the ingest capabilities of Cassandra with the query capabilities you might expect from HANA. It provided the convenience of a familiar relational database with the extended data science capabilities that you might look for in Spark.
If these capabilities sound like something you need, Contact us for a demo , or download the trial edition to try it out for yourself.


