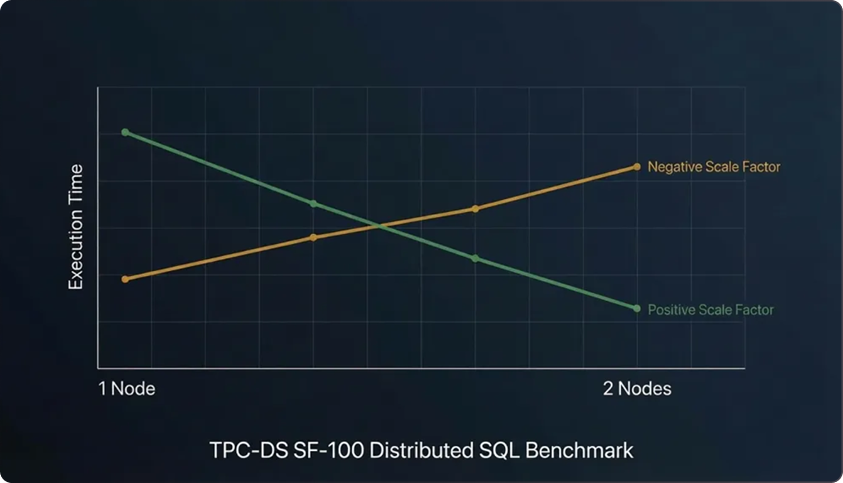
A comparative performance evaluation of Kinetica 7.2.3.2 and ClickHouse 25.10.1 on the TPC-DS
SF-100 benchmark, run on identical hardware. Kinetica completed 100% of the 99 queries while
ClickHouse completed 62–66%, and ran 2.5×–16× faster across single- and two-node configurations —
while ClickHouse exhibited negative scaling. This study highlights why workload completeness and
distributed execution efficiency matter as much as raw scan speed.
Today we’re excited to share a new integration that brings the speed and flexibility of DuckDB
together with the real-time analytical power of Kinetica. By leveraging DuckDB’s Postgres
protocol extension alongside Kinetica’s support for the PostgreSQL wire protocol, you can now
query live Kinetica datasets directly from DuckDB — mixing real-time operational analytics with
local, interactive SQL. This unlocks an incredibly productive developer experience: use DuckDB
as your local analytics workbench, join Kinetica data with Parquet/CSV files, prototype queries
against live tables, and orchestrate workflows without writing custom connectors or glue code.
Why This MattersTools like DuckDB have transformed local, interactive analytics. Analysts and
engineers can explore datasets stored in many formats right from their laptop — fast and without
infrastructure overhead. But until now, extending that same ergonomics to live analytics
databases required someone to build and maintain a custom connector layer. Now, because
Kinetica natively speaks the Postgres wire protocol and DuckDB supports attaching
Postgres-compatible endpoints, you can treat Kinetica just like another data source in
DuckDB — no translation layer, […]
Logistics optimization is becoming more complex: multi-hop routing, diverse transportation
modes, SKU-level requirements, service constraints, and constantly shifting supply-demand
conditions — leaving many organizations stitching together multiple tools, custom code, and
external solvers to try to keep up. We think there’s an easier route…
Kinetica’s Multiple Supply Demand Optimization (MSDO) solver is a native, SQL-driven
engine that computes optimal routing and allocation across complex, multi-modal supply chains —
matching supplies to demands while honoring constraints such as transport modes, capacities,
penalties, priorities, and detailed item specifications. Classic MSDO focused on solving the
optimal path from supply to demand in a single step. In this article we’ll discuss recent
updates including multi-step optimization and specification-aware matching, that
bring Kinetica’s hybrid OLAP/Graph closer to becoming a complete, end-to-end
logistics solver — capable of modeling and executing complex multi-hop logistics flows
through a single, concise SQL statement inside the database. No more separate optimization
engines. No external orchestration layers. No custom Python pipelines — routing, constraints,
specification matching, and even multi-step optimization — all created/executed in a single
platform. MSDO’s multi-modal […]
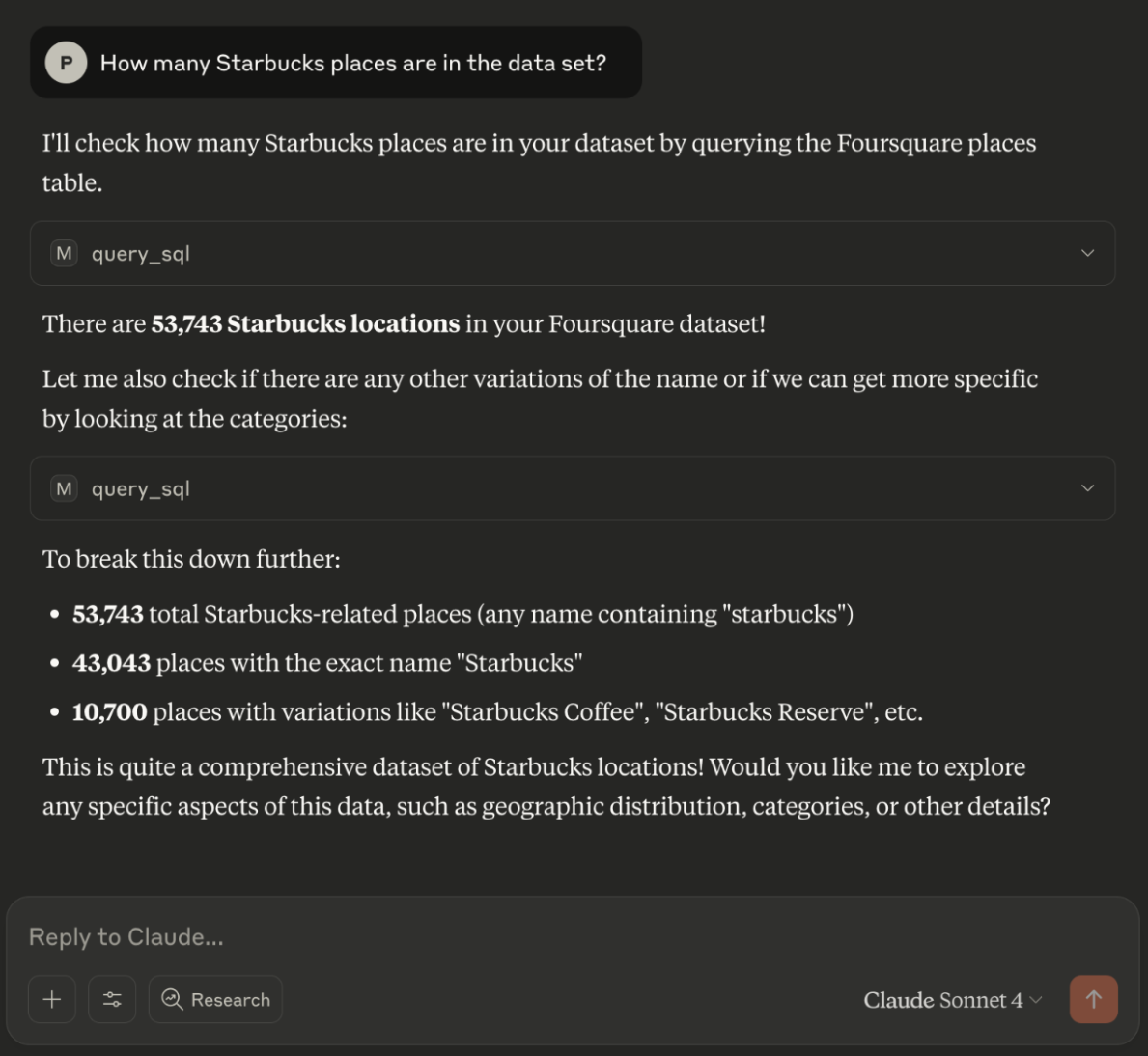
Can we use LLMs to interrogate massive amounts of real world data? We built a Model Context
Protocol (MCP) server for Kinetica, hooked it up to Claude and asked questions about a
104-million-row Foursquare Places dataset to test this. This post walks through what
worked, what didn’t, and why Kinetica + MCP might be one of the cleanest ways to build AI-native
interfaces for large data. Why You Should Use MCP + Kinetica Let’s first break down why
you should use Kinetica for your AI applications. MCP is engine-agnostic, but its usefulness
depends on the backend. Kinetica offers real-time, multimodal analytics that make MCP much more
powerful in practice. You can see our latest benchmarks for a more detailed performance
comparison. We’re proud of how Kinetica stacks up against ClickHouse, BigQuery, and SingleStore,
especially when it comes to complex SQL workloads on massive data. What we Built We built the
Kinetica MCP server to let LLMs like Claude interact directly with live Kinetica data. No
plugins, wrappers, or […]
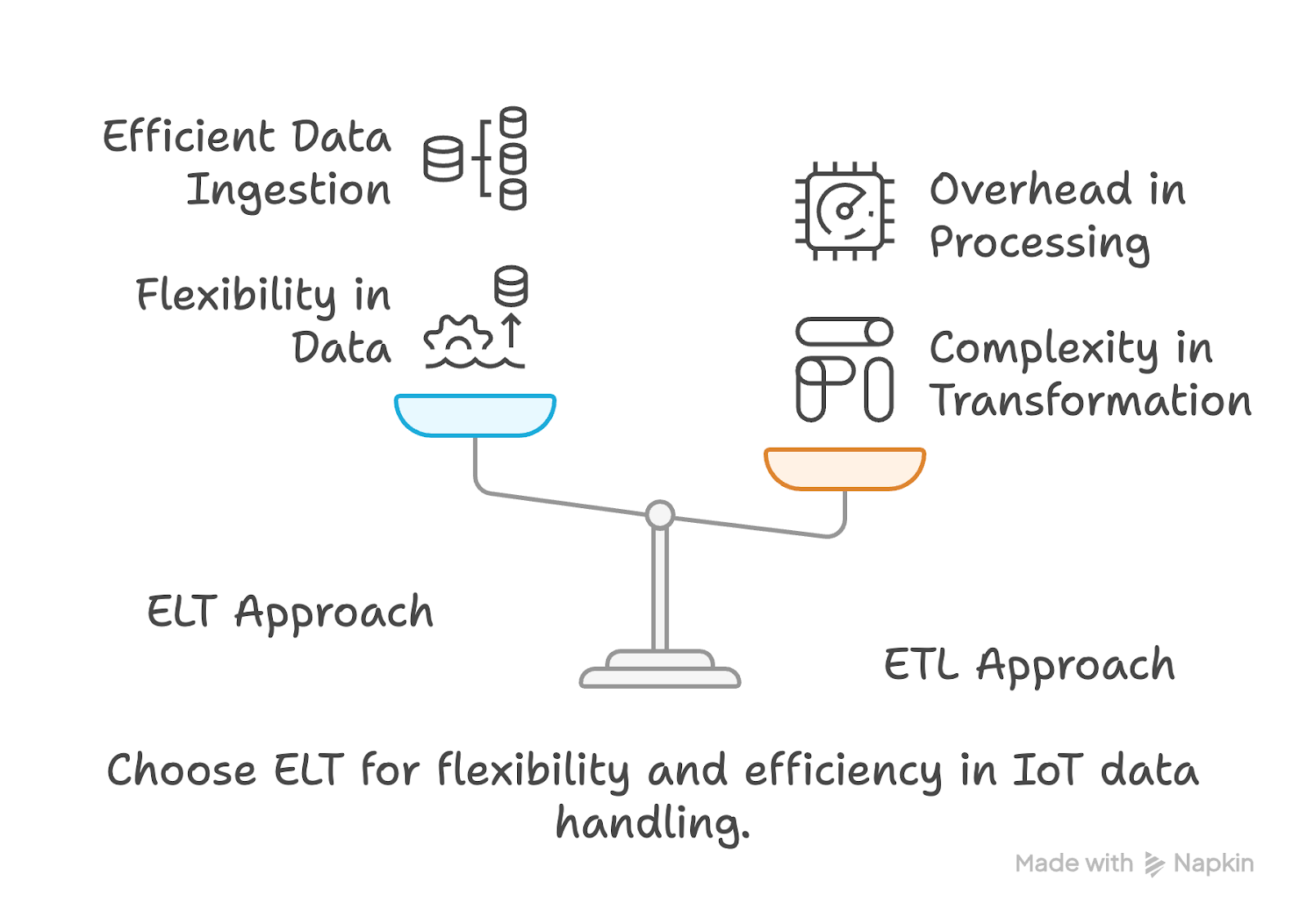
The rise of IoT has led to an explosion of real-time data—from logistics fleets to power grids
to factory floors. Sensors are constantly emitting data. This telemetry unlocks immense value:
smarter routing, predictive maintenance, and responsive infrastructure. But here’s the catch:
this data often arrives as deeply nested JSON, emitted either directly by the devices or through
aggregation gateways. Traditional databases choke on this complexity. They force teams to
flatten data upfront via ETL pipelines—slow, brittle, and ill-suited for real-time demands. ✨
Kinetica: Real-Time Analytics on Raw Sensor Data Kinetica eliminates the need for external ETL.
It ingests raw nested JSON directly, stores it in native JSON columns, and lets you query it
with standard SQL—all at sub-second speeds. Let’s walk through how this works, using some sample
sensor JSON data. Sample Nested JSON Payload This one JSON object includes: This is a common
telemetry structure—rich, flexible, and hard to wrangle using traditional SQL. Step 1: Ingest
the raw JSON directly into Kinetica With Kinetica, you skip the […]
Introduction: The Limits of Embeddings and Graphs in Isolation Graph databases are powerful
tools for modeling relationships, but the connections between the nodes do not necessarily
follow a semantic intuition, or language rules (LLM). Meanwhile, embedding models – that
transform general knowledge graphs into vector embeddings using algorithms like word2vec or our
recently published concept[1] which computes and flattens many graph predicates over vector
spaces–fail to accurately capture both local and remote affinities represented by
infinite-dimension graphs as limited-dimension vectors. The main reason is that the relations
are mere ad-hoc connections that do not necessarily follow a pattern — however, the best pattern
for query accuracy is the graph itself. Hence, the reverse process, i.e., injecting vector
similarities as connections to the graph where its schema (ontology) is purpose built further
improves graph’s abilities with far reaching potentials – hops away relations are by definition
much more reliably accurate as they are rectified by connections from nodes that are proven to
be similar. What if you could combine […]
Introduction Most analytics platforms struggle to support the full range of operations required
for complex real-world problems. Spatial, graph, time series, and vector search capabilities are
often siloed into separate tools, forcing users to stitch together workflows across multiple
systems—creating inefficiencies, bottlenecks, and integration challenges. Kinetica eliminates
this friction by unifying these advanced analytics within a relational framework. Users can
perform deep analytical operations—such as computing isochrones, solving shortest paths, and
aggregating spatial zones—within a single SQL query, streamlining decision-making that would
otherwise demand multiple systems and custom engineering. This blog demonstrates how Kinetica’s
built-in capabilities enable high-speed reachability and coverage analysis with remarkable
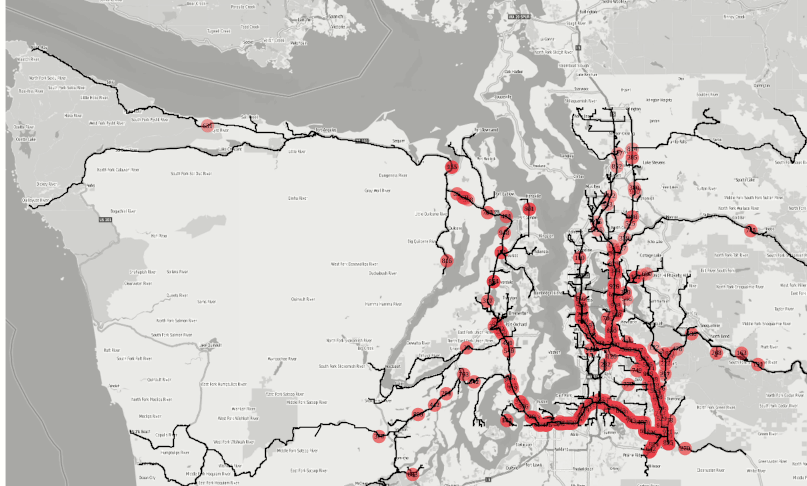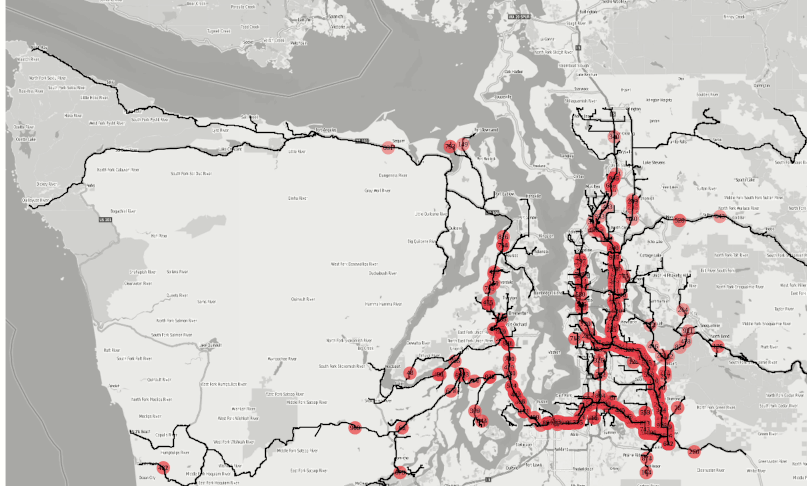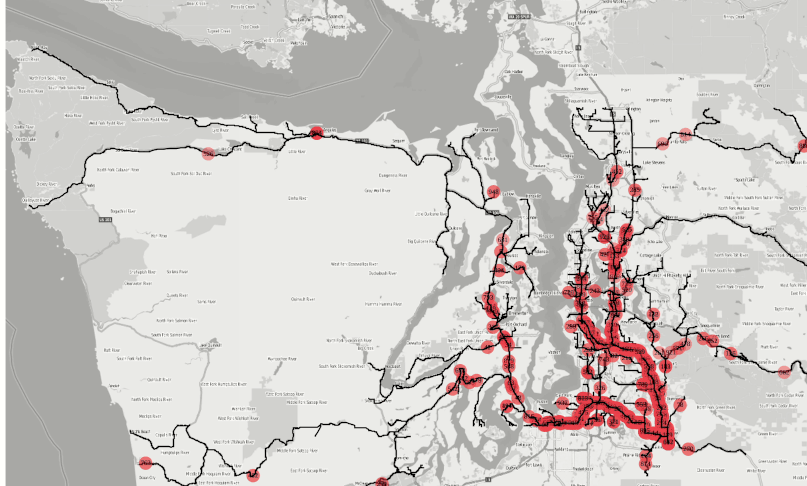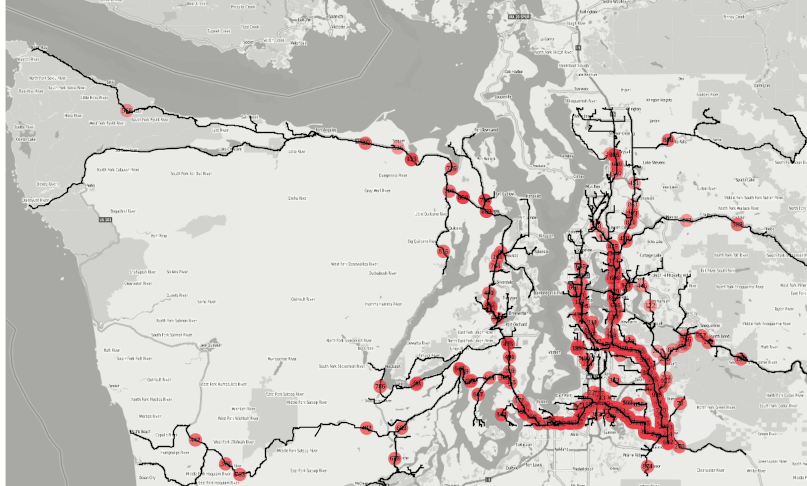
efficiency. Figure 1 : The animation is created from the agglomerated isochrones from 500+ fire
stations in the Seattle area within 1,2,3,4,5 and 10 minutes successively by applying the SQL
statement shown in Figure 3. How long does it take for a fire truck to reach a certain location
from all available stations is an important question for many interested parties; for the
home owner […]
A key challenge for any database, whether distributed or not, is the constant movement of data
between a hard disk and system memory (RAM). This data transfer is often the source of
significant performance overhead, as the speed difference between these two types of storage can
be dramatic. In an ideal scenario, all operational data would reside in memory, eliminating the
need to read from or write to slower hard disks. Unfortunately, system memory (RAM) is
substantially more expensive than disk storage, making it impractical to store all data
in-memory, especially for large datasets. So, how do we get the best performance out of this
limited resource? The answer is simple: use a database that optimizes its memory use
intelligently. Prioritizing Hot and Warm Data Kinetica takes a memory-first approach by
utilizing a tiered storage strategy that prioritizes high-speed VRAM (the memory co-located with
GPUs) and RAM for the data that is most frequently accessed, often referred to as “hot” and
“warm” data. This approach significantly reduces the […]
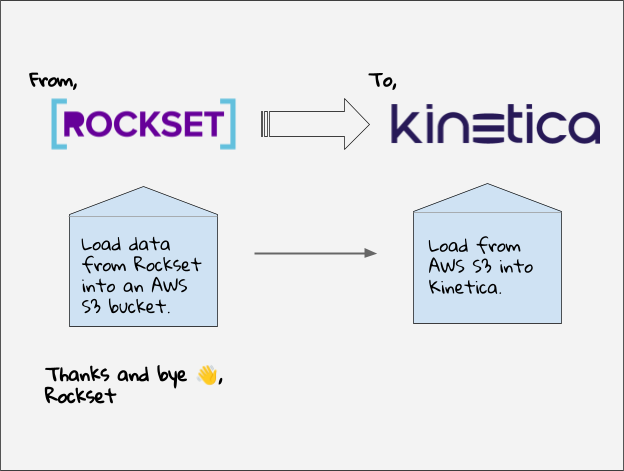
With Rockset being sunsetted by September 30th, many of its customers are left in the lurch,
seeking a reliable alternative for their real-time data analytics needs. Kinetica stands out as
the optimal choice, engineered specifically for real-time data analytics. Why Choose Kinetica
for Your Rockset Migration? Kinetica leverages GPU acceleration to ingest millions of records
and execute complex OLAP, spatial, time series, graph analytics and vector search using SQL. Our
platform is designed to match or outperform Rockset in handling real-time data analytics and
similarity search, providing a seamless transition with enhanced performance. Start Free With
Kinetica Cloud in Just Minutes Create a staging S3 bucket Export Your Rockset Data to AWS S3
Load Data From AWS S3 Into Kinetica Migrate Your Queries Need Help?
The release of ChatGPT marked a significant shift in how people interact with technology by
introducing a conversational mode of inquiry using natural language to surface insights. This
trend is now extending to enterprise analytics, as evidenced by OpenAI’s acquisition of Rockset.
The trend is clear: traditional BI tools and data science languages are giving way to natural
language and conversational interfaces. Real-time Multimodal Capabilities for AI Copilots
Kinetica’s database engine is uniquely suited for AI copilots because it excels in two critical
areas: analytical range and low-latency responses. Conversational inquiries can lead to
unpredictable and diverse types of queries. Kinetica supports a wide array of analytical tasks,
including spatial, OLAP, graph, time series, and vector search, ensuring comprehensive
analytical coverage required to support a conversation mode of inquiry. Additionally, when
dealing with enterprise-scale data, maintaining a conversational flow requires fast query
responses. Kinetica’s architecture, leveraging modern CPUs and GPUs, guarantees high-speed
processing, allowing for quick and seamless transitions from language to insight.
Furthermore, the speed with which […]
Imagine waking up one morning to find that your local gas station has run dry, leaving you
stranded without fuel. This was the harsh reality for millions of Americans in May 2021, when
the Colonial Pipeline ransomware attack disrupted the fuel supply across the Eastern United
States. DarkSide, a group of hackers, infiltrated the pipeline's systems, causing widespread
panic and fuel shortages. This incident highlights the growing vulnerability of our energy
infrastructure to cyberattacks.
Kinetica, the GPU-powered RAG (Retrieval Augmented Generation) engine, is now integrating deeply
with NVIDIA Inference Microservices for embedding generation and LLM inference. This integration
allows users to invoke embedding and inferencing models provided by NIM directly within
Kinetica, simplifying the development of production-ready generative AI applications that can
converse with and extract insights from enterprise data. NIM packages AI services into
containers, facilitating their deployment across various infrastructures while giving
enterprises full control over their data and security. By combining these services with
Kinetica’s robust compute and vector search capabilities, developers can easily build data
copilots that meet rigorous performance and security requirements. The queries below show how
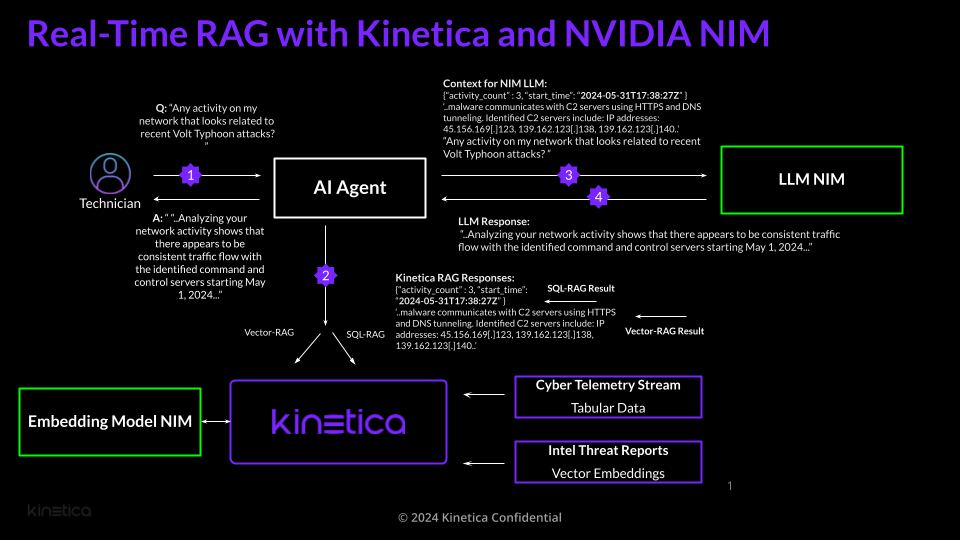
you can connect Kinetica to NIM with just a few SQL statements. A cybersecurity chatbot We are
developing a cybersecurity chatbot using this stack. The chatbot processes two types of sources:
Given a user prompt, the chatbot interfaces with tabular data sources and text-based knowledge
from documents to provide an appropriate response. The diagram below outlines the architecture
of the […]
Until recently, pure vector databases like Pinecone, Milvus, and Zilliz were all the rage. These
databases emerged to meet a critical need: Large Language Models (LLMs) often require
information beyond their training data to answer user questions accurately. This process, known
as Retrieval Augmented Generation (RAG), addresses that need by fetching relevant text based
information using a vector similarity search. RAG powers applications like ChatGPT, enabling
them to act on information beyond their training, such as summarizing news and answering
questions about private documents. By storing and retrieving relevant information to augment an
LLM’s knowledge, vector databases played a crucial role in the first phase of Generative AI,
facilitating the adoption of tools like ChatGPT. So why are vector databases being
replaced??? While some vector databases will continue to provide value, they are increasingly
being replaced by a new breed of multimodal retrieval engines that offer more than just vector
search. This shift is driven by the limitations of vector databases in two critical areas: 1.
Inability to […]
Every moment, trillions of entities—vehicles, stock prices, drones, weather events, and
beyond—are in constant motion. Imagine the vast opportunities and insights we could uncover by
monitoring these objects and detecting pivotal events as they unfold, in real time. Such a task
demands an analytical engine that can ingest high velocity data streams, execute sophisticated
queries to pinpoint critical events and insights, and deliver instantaneous results to be acted
upon. This is precisely the challenge you can address with Kinetica and Confluent. Kinetica is a
GPU accelerated database that excels in complex real-time analysis at scale, while Confluent,
built upon Apache Kafka, provides robust data streaming capabilities. Together, they forge a
powerful architecture that unlocks the full potential of streaming data. My aim with this blog
is to demonstrate the power of Kinetica and Confluent in action in three simple steps. You
can try all of this on your own by uploading this workbook into your free Kinetica instance. All
of the data is open for access. You will […]
We are thrilled to announce that Kinetica has now joined the Connect with Confluent Partner
program. This collaboration merges the unparalleled speed of Kinetica’s GPU-accelerated database
with the data streaming capabilities of Confluent Cloud, delivering insights on high-velocity
data streams in mere seconds. Why This Partnership Matters Confluent is at the forefront of
streaming data technology, offering best-in-class capabilities that make it an industry leader.
Kinetica enhances this proposition by ingesting these high velocity data streams and fusing them
with contextual data, enabling the execution of complex SQL queries – all in real time. This
unlocks opportunities for advanced analytics on real-time data feeds, setting a new standard for
immediate, data-driven insights. Fast Ingest Kinetica’s multi-head ingest is designed to handle
the volume and velocity of Kafka topics effortlessly. Its lockless architecture allows query
execution while data is being streamed in. Both of these features together slash data latency
significantly. Contextual Insights Together, Kinetica and Confluent create an ecosystem where
data is not just collected but is swiftly […]
You’ve seen how Kinetica enables generative AI to create working SQL queries from
natural-language questions, using data set up for the demonstration by Kinetica engineers.
What about your data? How can you make Kinetica respond to real SQL queries about data
that belongs to you, that you work with today, using conversational, natural-language questions,
right now? You’re about to see how Kinetica SQL-GPT enables you to have a conversation with your
own data. Not ours, but yours. With the built-in SQL-GPT demos, the data is already
imported, and the contexts that help make that data more associative with natural language,
already entered. When your goal is to make your own data as responsive as the data in our
SQL-GPT demos, there are steps you need to take first. This page shows you how to do the
following: STEP 1: Import your Data into Kinetica Kinetica recognizes data files stored in the
following formats: delimited text files (CSV, TSV), Apache Parquet, shapefiles, JSON, and
GeoJSON [Details]. For Kinetica to […]
I think one of the most important challenges for organizations today is to use the data they
already have more effectively, in order to better understand their current situation, risks, and
opportunities. Modern organizations accumulate vast amounts of data, but they often fail
to take full advantage of it because they struggle finding the right skilled resources to
analyze it that would unlock critical insights. Kinetica provides a single platform that can
perform complex and fast analysis on large amounts of data with a wide variety of analysis
tools. This, I believe, makes Kinetica well-positioned for data analytics. However,
many analysis tools are only available to users who possess the requisite programming
skills. Among these, SQL is one of the most powerful and yet it can be a bottleneck
for executives and analysts who find themselves relying on their technical teams to write the
queries and process the reports. Given these challenges Nima Neghaban and I saw an opportunity
for AI models to generate SQL based on natural […]
Prior to the emergence of machine learning, and particularly “deep learning,” I was an ML
skeptic. Judging from what I saw from the state of the art at the time, I’d say there was
no way to program a CPU or a GPU — each of which, after all, is just a sophisticated instance of
a Turing machine — to make it exhibit behaviors that could pass for human intelligence. It
seemed like a sensible enough stance to take, given that I spent the bulk of a typical work week
translating ambiguous requirements from customers into unambiguous instructions a computer could
execute. Algorithmic neural networks had been around since the 1950s, yet most AI
algorithms had been designed to follow a fixed set of steps with no concept of training.
Algorithms are sets of recursive steps that programs should follow to attain a discrete result.
While machine learning does involve algorithms at a deep level, what the computer appears to
learn from ML typically does not follow any […]
To provide the best experiences, we use technologies like cookies to store and/or access device
information. Consenting to these technologies will allow us to process data such as browsing behavior or
unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and
functions.
Cookie Policy