You have questions. We have answers! As we pave a new market for hardware-accelerated databases, we’re frequently running into the same questions with eager-to-learn prospects and researchers. Here are some of the most popular ones, and you can find many more on the ‘Frequently Asked Questions‘ page.
So, what exactly is Kinetica?
Kinetica is a distributed, in-memory database accelerated by GPUs that can simultaneously ingest, analyze, and visualize streaming data for truly real-time actionable intelligence. Kinetica leverages the power of many core devices (such as GPUs) to deliver results orders of magnitude faster than traditional databases on a fraction of the hardware
OLAP? OLTP? Or Both?
Kinetica is a vectorized columnar database designed for analytics (OLAP) workloads. Kinetica was built from the ground up to leverage the parallel compute power of the GPU for fast response to analytic queries on large datasets. Kinetica stands out when used with streaming data, and high-cardinality data. Kinetica is not typically used as a system of record, but is a great analytics complement to an OLTP system.
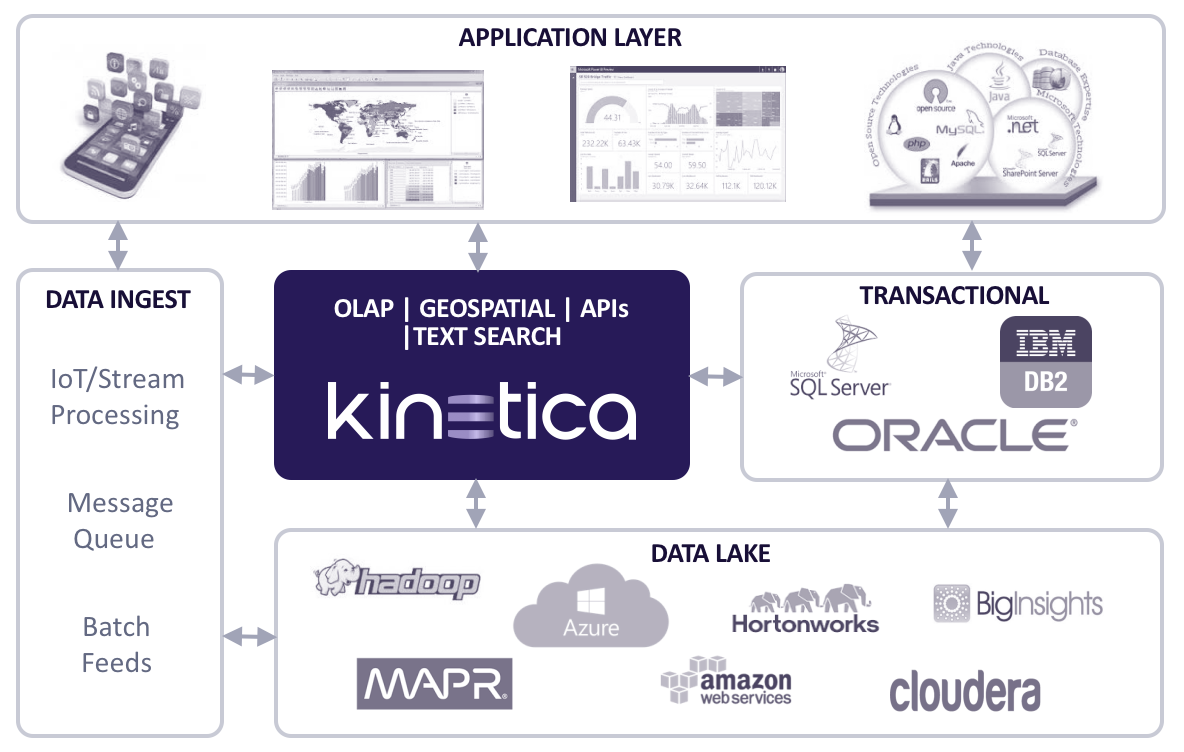
Is Kinetica scalable?
Yes, Kinetica is designed to be highly and predictably scalable – both up and out.
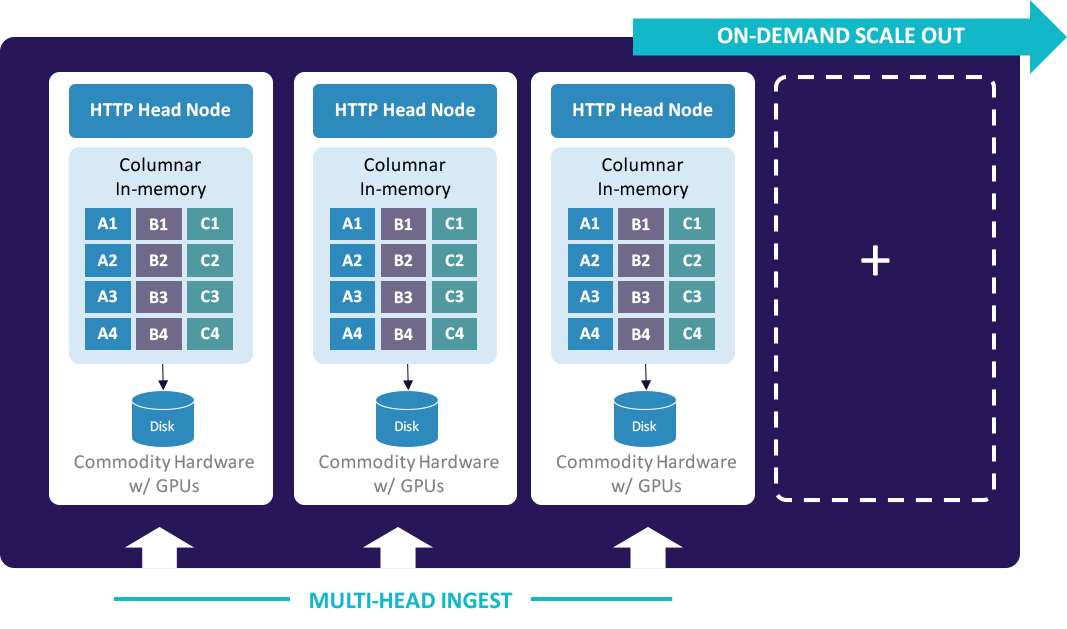
Kinetica runs on industry standard hardware, equipped with GPUs. Kinetica scales horizontally by simply adding nodes to distribute the data. A cluster can be scaled up at any time to increase storage capacity and processing power, with near-linear scale processing improvements for most operations. Sharding of data can be done automatically, or specified and optimized by the user.
A typical cluster might consist of multiple identical nodes, each with a couple GPUs and 1TB RAM per node. The GPU delivers almost linear scalability, which makes it viable to do real-time analytics on a 10TB, or even a 100TB dataset, with predictable hardware demands.
What performance increase can I expect?
Harnessing the parallel processing power of many core devices (such as GPUs), an end user of Kinetica can expect anywhere from 10x-100x faster performance (ingest, analytics, and visualization) compared to some of the most advanced in-memory databases.
Kinetica was recently tested against a leading state-of-the-art in-memory system by a major retailer. The existing system was not meeting SLAs as they attempted to correlate weather and social media signals to predict demands on inventory.
The Kinetica cluster, powered by GPUs, proved to be over 100 times faster on their top-10 hardest queries. Furthermore, the Kinetica cluster achieved these improvements on a cluster that was 1/10 the size. This was on real-world data and workloads : star schema, fact tables of 150 billion rows related to multiple dimension tables in a classic distributed join with GROUP BYs.
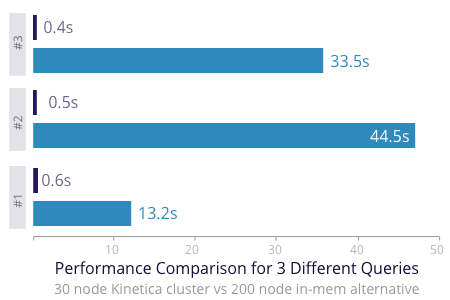
These impressive metrics are seen against any CPU-based in-memory system. While placing data in memory reduces latency, and is a critical component to building a fast database, alone it is not enough. Once data is in memory, the bottleneck then becomes the compute resources available to process the data. The GPU solves this.
Structured or unstructured data?
Kinetica functions much like a traditional structured relational database and requires data in a structured format. To get started, create a table, set a schema, start inserting rows, and you’re ready to start doing analytics. The GPU specifics are abstracted from the DBA or for the developer.
How does Kinetica integrate with open source and commercial frameworks?
Kinetica’s native REST API makes it available to a wide variety of technologies. Specialized libraries are available for Java, Python, C++, Javascript and Node.js. Integration also exists with many open source and commercial frameworks including Apache NiFi, Spark and Spark Streaming, Storm, Kafka and Hadoop. ODBC and JDBC drivers enable SQL query and integration with industry-standard BI tools.
View the entire list of Kinetica connectors, and API options.
How do I get started?
Here are a few ways to get up and running with Kinetica:
- Take Kinetica on test-drive through the interactive demo. Here you can interactively explore a selection of datasets and experience the power of GPU-accelerated compute.
- The next step is to try it with your own data, your own schemas and your own queries. Fill out the form at the bottom of this page and we can set you up a trial environment for you to experience it yourself.
- Kinetica also offers two easy programs to help you jumpstart installation and application development with Kinetica.
The full gamut of questions is listed on our FAQ Page
We welcome additional questions! To learn more, or if you’d like to get your hands on a trial, call us at 888 504-7832 or fill out a contact form.


