Today, we're excited to announce that TensorFlow™ — the industry's leading open-source library for machine intelligence — now comes bundled with Kinetica. This will make it easier for enterprises to take advantage of distributed deep-learning as part of a cohesive database solution.
TensorFlow is rapidly becoming the go-to open-source library for machine intelligence and deep learning. But as businesses seek to harness the value and opportunities that deep learning offers, they must also solve other data challenges: such as how to feed these systems with operational data, how to store data so there is flexibility in feature selection, where to store output, and how to make AI models available to line-of-business decision makers.
With Tensorflow on Kinetica, businesses can now manage complex, compute-intensive machine-learning workloads as part of a comprehensive database solution. The combination of Kinetica and TensorFlow offers a unified solution for data preparation, model training, and model deployment into production. And because Kinetica is designed to leverage the GPU's parallelization capabilities, it stands to accelerate deep learning pipelines by 10-100X.
Accelerating the Deep Learning Pipeline
For organizations wrestling with the speed, scale, and size of data generated by business apps and new data sources – such as social media, sensors, and machine log data – deep learning has emerged as a viable strategy to discover actionable insights in your data by automatically uncovering patterns, anomalies, and relationships.
But deploying deep learning within the enterprise isn't easy. The complex nature of deep learning workloads means that you'll need to master compute, throughput, data management, interoperability, elasticity, security, user experience, and operationalization capabilities. Technologies such as GPUs, in-memory, distributed computing, and open source deep learning frameworks such as TensorFlow are promising, but enterprises demand simpler, converged, and turnkey solutions to deliver on the promise of deep learning.
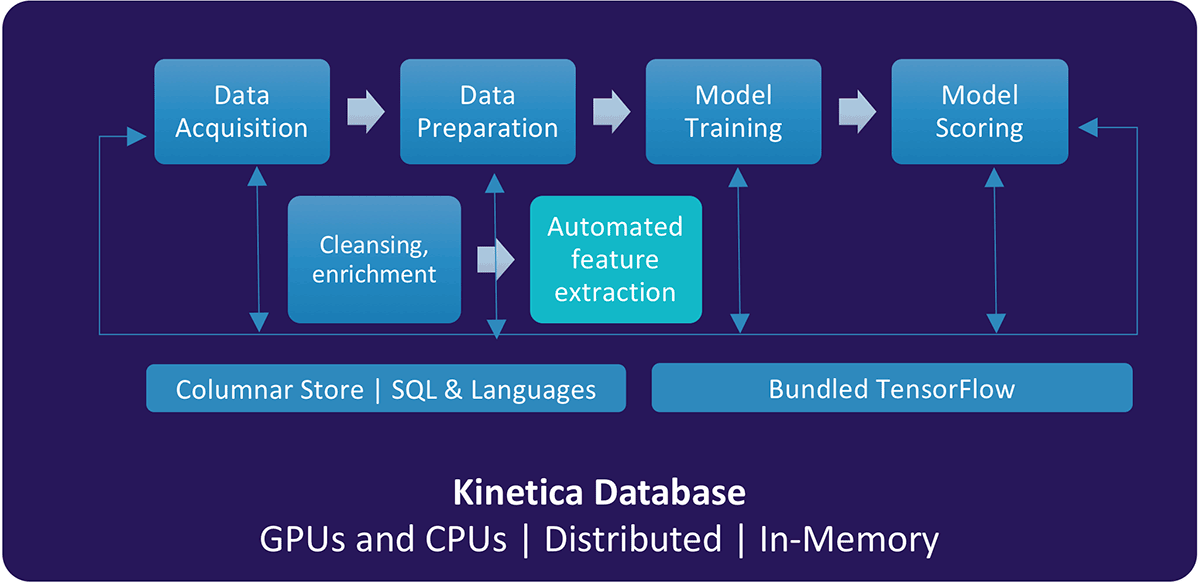
With Kinetica, you can simplify and accelerate the entire deep learning pipeline with data generation, model training, and model serving. Here's how Kinetica adds value to the deep learning pipeline:
Data Generation
Data generation refers to acquiring and preparing datasets to train deep learning models. Kinetica v6.0.1 offers cutting-edge features such as:
- Data acquisition: Kinetica provides connectors for data-in-motion and data-at-rest with multi-head ingest so you can integrate millions of rows of data across disparate systems in seconds and make it available for model training.
- Data persistence: Kinetica persists data in simple structures such as tables, rows, columns, and views. Native data types such as integer, long, timestamp, float, decimal, string, byte arrays, and geospatial data types such as points, shapes, tracks, and labels store and manage multi-structured data, so your text, images, spatial, and time-series data is easily accessible for deep learning.
- Data preparation: Kinetica's in-memory database delivers millisecond response times to explore and prepare massive datasets. It supports languages such as SQL, C++, Java, and Python, simplifying data preparation, regardless of your skillset.
Model Training
Model training is the biggest bottleneck and most resource-intensive step in deep learning pipeline. Kinetica features an extensible UDF framework to plugin open source machine learning libraries such as Caffe, Torch, MXNet and more for in-line model training. TensorFlow comes bundled with the database and is available via the UDF framework, so data preparation, model training, and model serving are done from a single solution. By using Kinetica, you'll benefit from:
- GPU acceleration: GPUs have thousands of small, efficient cores that are ideal for performing repeated similar instructions in parallel. This makes them well-suited for compute-intensive deep learning training workloads on large datasets. Kinetica's native GPU-based parallel processing removes the need for data sampling and expensive, resource-intensive tuning, so you benefit from 100X performance improvements on commodity hardware.
- Distributed, scale-out architecture: A Kinetica cluster contains data sharded and processing distributed across multiple nodes to leverage parallelization for ingest, data persistence, and model training. Easily add more nodes for scale-out to improve performance and system capacity.
- Vector and matrix operations: Kinetica's vectorized database uses purpose-built in-memory data structures and optimized processing to take advantage of processing improvements offered by modern processors. Kinetica delivers an order of magnitude performance improvement on vector and matrix operations that you typically use for deep learning workloads.
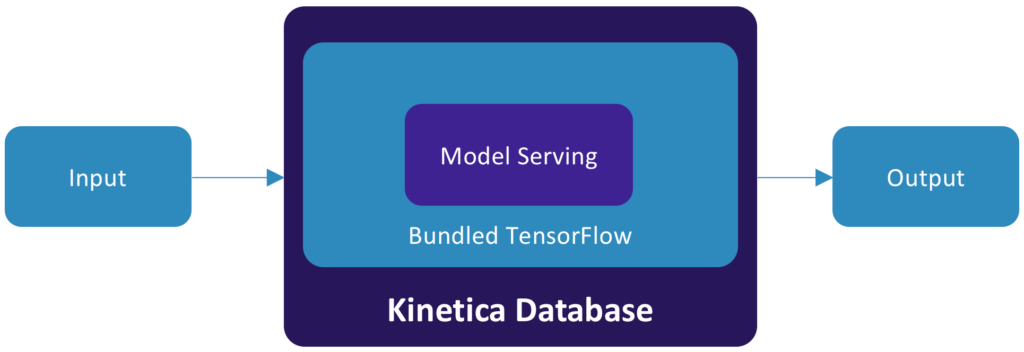
Model Serving
Kinetica operationalizes deep learning by making the models available for scoring input data in the same database used for data generation and model training. With bundled TensorFlow, models can be scored in-line for fast scoring and better predictions.
Industry Examples
As an example, take a look at how organizations in retail, insurance, and finance can use Kinetica and TensorFlow together to solve business problems:
Retail recommendation engines:
Retailers can use the bundled solution to build better recommendation engines and improve customer experience and conversion with rich, contextual, and relevant recommendations. Specific use cases include:
- Smart membership renewal reminders: For membership-based retailers, TensorFlow-based deep neural networks (DNN) can be trained to intelligently predict the right time and frequency to flag a customer for membership renewal based on shopping history, recency and frequency of store visits, transaction size, and profile. Kinetica helps with data acquisition, preparation, model training, and serving to target customers at the right time and improve retention.
- Automatically build the shopping cart: TensorFlow-based DNN models can be trained on POS data to uncover hidden relationships and deliver contextual, relevant recommendations. Kinetica is optimized to process massive matrixed POS datasets at scale to discover relationships between SKUs, shoppers, stores, and regions and deliver relevant offers. Shoppers can walk into the store, scan an item, and have their entire shopping cart built based on the selected item and appropriate recommendations.
Image processing in insurance:
Auto and property insurers can use the image processing capabilities of the bundled solution to expedite and streamline the claims handling process. Deep neural networks can be trained to process images, identify objects, and assess damage. These trained models can then be used to estimate repair costs based on images uploaded by customers. Kinetica and TensorFlow provide the backbone to store images, train models and serve models in real time for faster claims processing.
Risk modeling in finance:
Financial services firms are using machine learning to run simulation and optimization algorithms to model uncertainty and price risk. The insights gained from the risk modeling process can then be used to drive trade decisions.
Kinetica draws upon years of work with enterprise customers, from large retailers to financial services companies. With TensorFlow bundled with Kinetica, you'll be able to quickly deploy deep learning models and build cognitive applications. Kinetica also includes numerous stability and performance enhancements to help you manage your most mission-critical workloads. Get set up with a trial environment today, so you can see for yourself how Kinetica can greatly improve and accelerate your deep learning pipeline.