For major retail companies, it is a crucial challenge for the business control center to know each store's in-stock quantities in real time. The world's largest retailers can have hundreds of thousands of SKUs, and sell thousands of dollars worth of products every second. At this scale, inventory misalignment can have an impact in the billions of dollars. Retailers need to ensure they have the optimal amount of inventory in stock and on the shelves at any given time.
Kinetica has solved this challenge for one of the world's largest retailers using real time streaming data ingest, user-defined functions, and high-performance multi-head key/value lookup capabilities. The solution discussed below has helped the retailer to make dynamic inventory replenishment decisions based on streaming data. With Kinetica, the retailer has been able to improve customer satisfaction, maximize revenue, and reduce losses to due inefficiencies like overstock and spoilage.
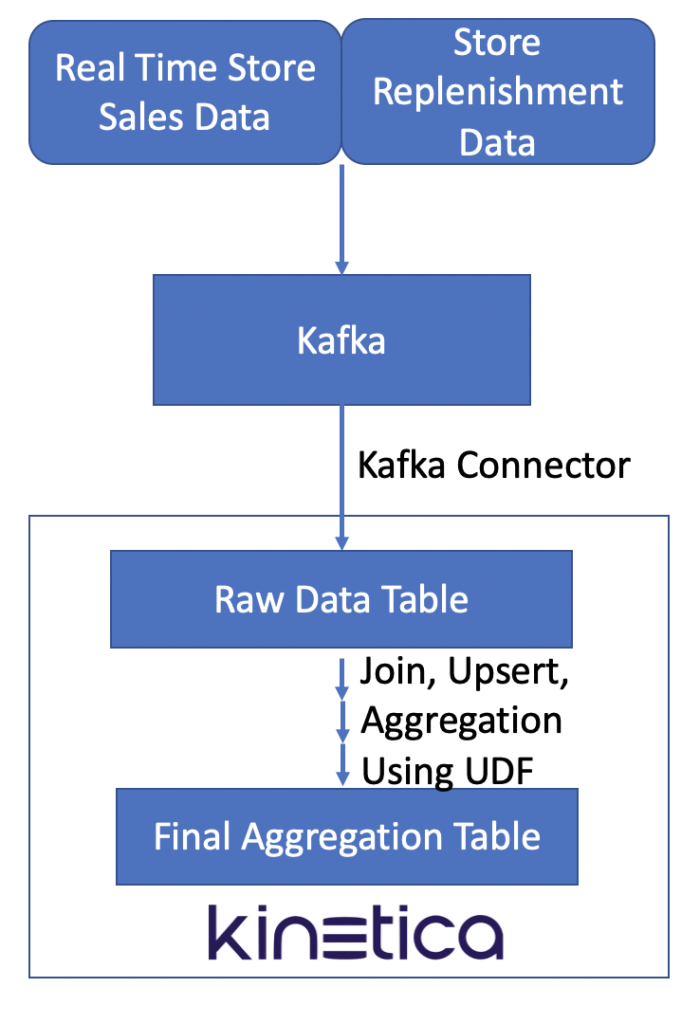
The use case has been implemented as such: Each store's real time sales transaction data is fed into Kinetica from a Kafka stream with Kinetica's Kafka-connector. While the sales data is being ingested into the source data table, a user-defined function (UDF) is scheduled to run every 10 seconds on the server side. It executes a series of queries that join the transaction data with a set of fact tables, bringing in the required fields to be aggregated on as defined by the business units, such as replenish_group_id, prime_item_id, etc.
The UDF will also take care of certain predefined item inventory change events during the day, such as when an item's replenishment group changes, an item's real quantity hard overwrites for a specific store, an item is completely removed from the inventory, etc. At the end of each UDF's execution cycle, the target aggregated table is refreshed to reflect all of the changes that happened in the last 10-second period.
With the final aggregated table in place and refreshed every 10 seconds, we are able to stand up a cluster of microservices by using Kinetica's fast multi-head key/value lookup API, to support querying each store's item inventory in real time.
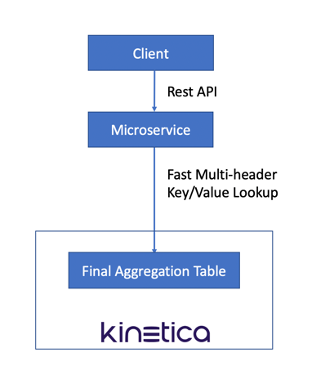

JMeter was used to test the microservice performance against a 5-node Kinetica cluster.
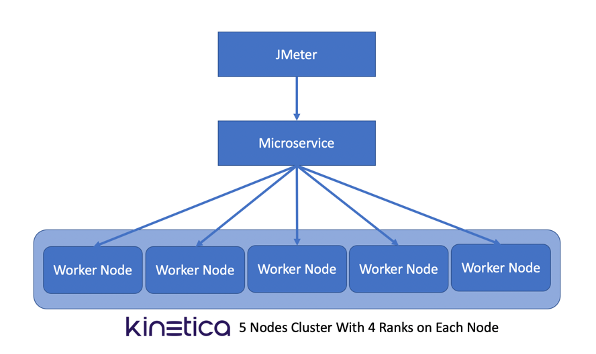
The JMeter test plan ran concurrently on 8 nodes against 8 instances of microservices. Overall, we achieved the service throughput at 13.6k/s per Kinetica node.
These capabilities allow Kinetica to grant new levels of visibility into inventory and the supply chain, enabling replenishment decisions to make agile decisions based on real-time information. Managers across stores and distribution centers can make ad-hoc decisions to move inventory in response to demand.
For more on this use case, see the case study linked here.
Jeffrey Yin is director of professional services at Kinetica.