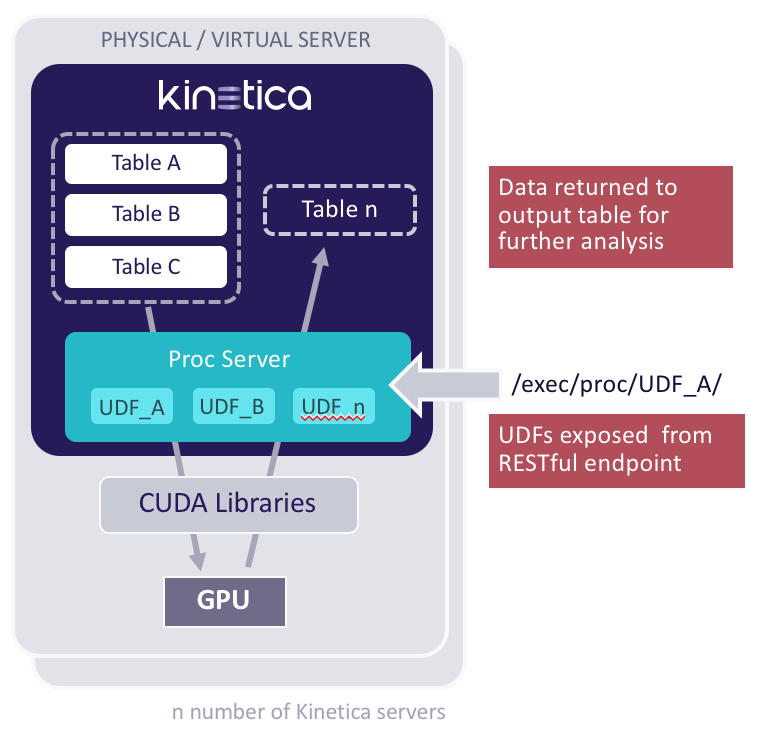
With Version 6.0, Kinetica introduces user-defined functions (UDFs), enabling GPU-accelerated data science logic to power advanced business analytics, on a single database platform.
User-defined functions (UDFs) enable compute as well as data-processing, within the database. Such 'in-database processing' is available on several high-end databases such as Oracle, Teradata, Vertica and others, but this is the first time such functionality has been made available on a database that fully utilizes the parallel compute power of the GPU on a distributed platform. In-database processing in Kinetica creates a highly flexible means of doing advanced compute-to-grid analytics.
This industry-first functionality stands to help democratize data science. Until now, organizations have typically needed to extract data to specialized environments to take advantage of GPU acceleration for data science workloads, such as machine learning and deep learning. Kinetica now makes it possible for sophisticated data science models to be developed and made available on the same database platform as is used for business analytics.
How it Works
UDFs and the associated orchestration API enable data to be processed with custom code that can draw on the power of distributed GPUs. UDFs have direct access to CUDA APIs, and can take full advantage of the distributed architecture of Kinetica. Because Kinetica is designed from the ground up to take full advantage of the GPU, users have an advanced mechanism for distributed computation.
UDFs are able to receive filtered data, do arbitrary computations, and then save output to a separate table. Such computations might include linear interpolation, anomaly detection, clustering, regressions, or risk simulations such as Monte Carlo analysis. The brute-force parallel compute power of the GPU delivers fast response which makes it more suitable for interactive analytics and experimentation.
GPUs are particularly well suited for the types of vector and matrix operations found in machine learning and deep learning systems. With in-database processing, custom functions will be able to call machine learning/artificial intelligence libraries such as TensorFlow, BIDMach, Caffe, Torch and others to work directly on data within Kinetica.
The orchestration API is available with C++ and Java bindings. Additional languages, such as Python will be available soon.
Why This Matters
As businesses move from deep analytics to predictive analytics, more and more operations stand to benefit from the parallel processing power of the GPU:
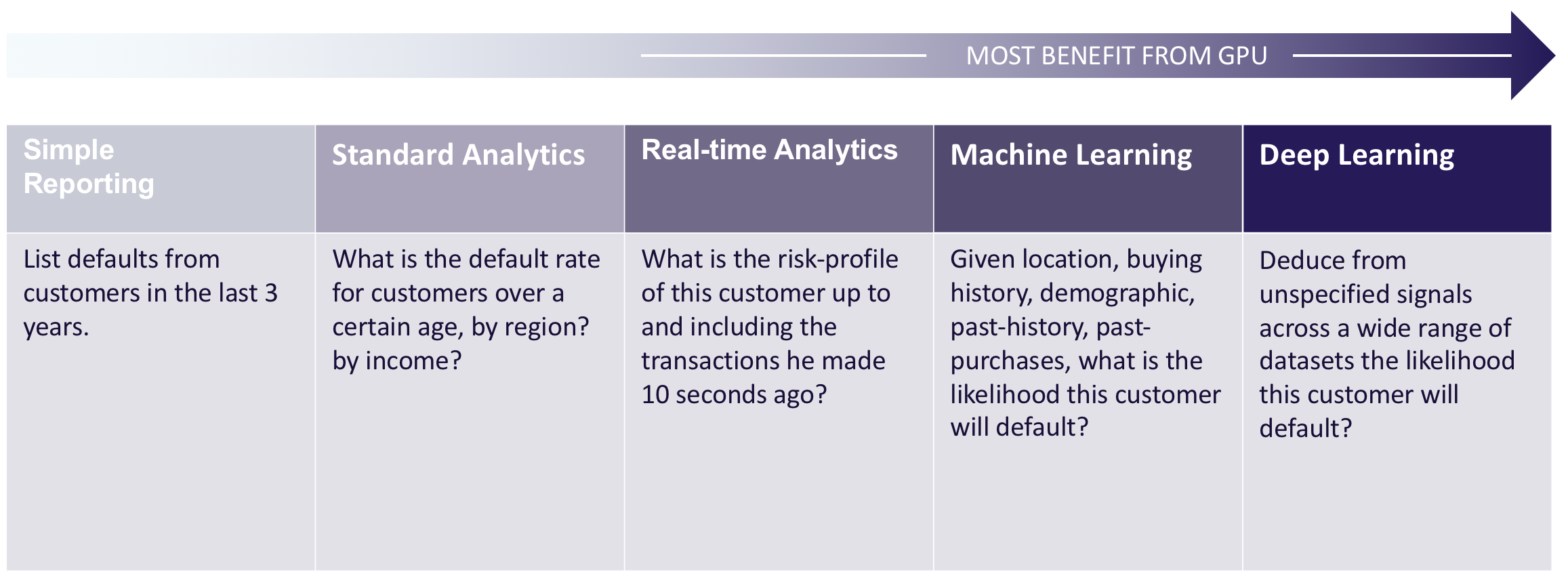
For organizations requiring low-latency response to sophisticated analytics on large datasets, Kinetica's in-database functionality will offer more customization and significantly faster operations. Pre-existing custom code that currently operates in separate systems can often be quickly reconfigured to run in Kinetica. UDFs open up a world of options for automating processes and performing business calculations within the analytics platform.
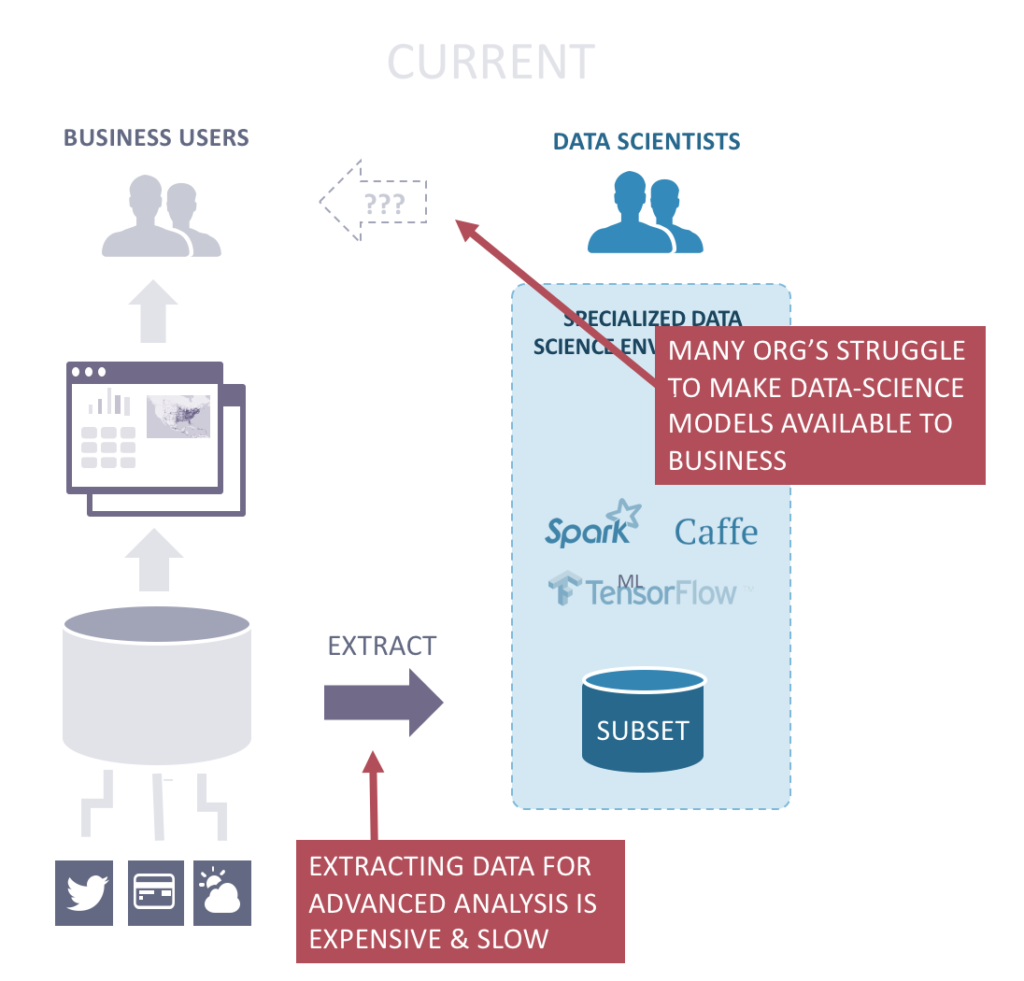
With predictive analytics and more advanced data science workloads, organizations have often resorted to exporting data to specialized high-performance computing (HPC) systems staffed by data scientists, who can work on these more complex problems. These groups demand GPU acceleration for the performance benefits. Because deep learning algorithms run several times faster on a GPU compared to a CPU, learning times can be reduced from weeks to hours, or from hours to minutes. This performance boost is critical because such algorithms need to be tweaked, then trained, and the time to iterate adds up.
Moving data to such specialized systems is cumbersome and slow, and it's common for data science to become disconnected from the business with no easy way to return models into production use.
What if it were possible to bring the data science modeling and business analytics together on the same platform?
This is what is now possible with in-database processing on Kinetica: BI and AI workloads can run together on the same GPU-accelerated database platform. Doing so eliminates the time and effort required to transform data and move it back and forth between a database and a separate data science system.
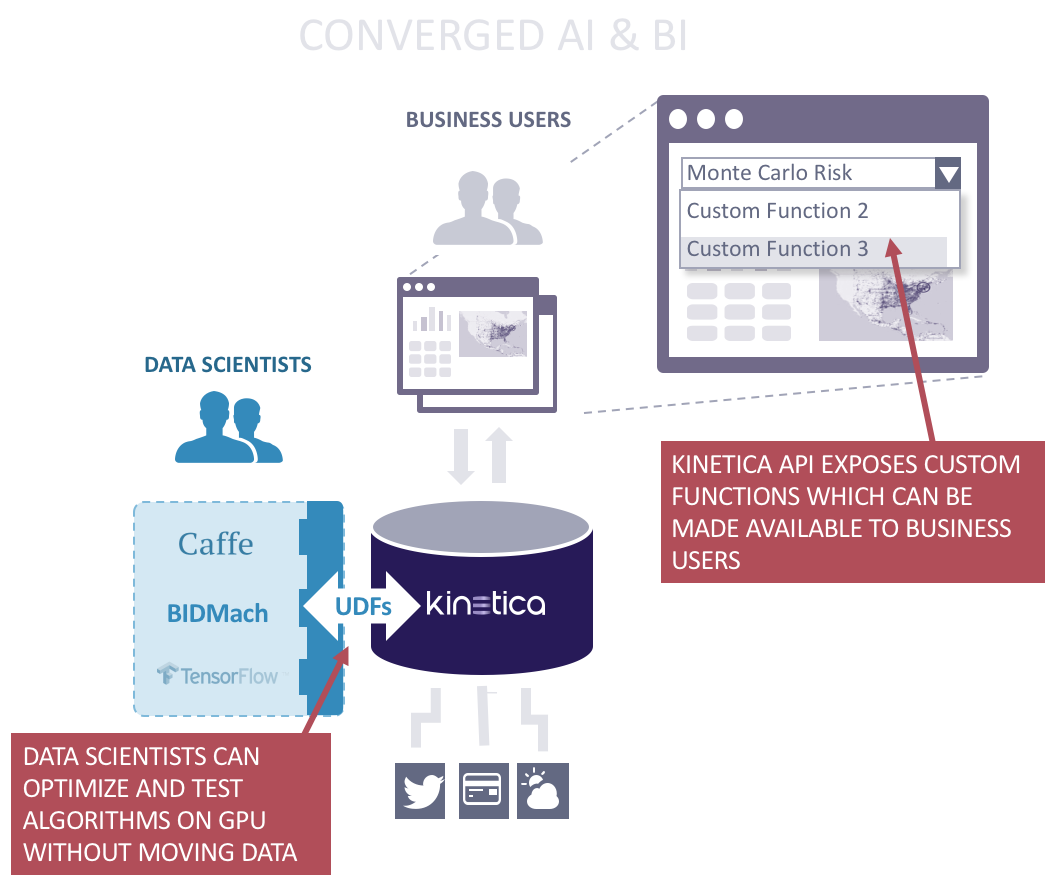
This empowers business users to do more sophisticated analysis without resorting to code. Data science teams can develop and test gold-standard simulations and algorithms while making them directly available on the systems used by end users. Foreseeably, in addition to querying data and running a 'GROUP BY', users could also call a Monte Carlo simulation, or other custom algorithms, straight from their BI tools. In this way, Kinetica stands to democratize data science.
Who Benefits
In-database processing on Kinetica appeals to customers that want to make advanced and predictive analytics available to line of business users. For example, fraud detection, trade decisioning, risk management, trend and pattern recognition are all use cases that can benefit.
Some use-cases we're currently involved with on include:
- Vehicle Design and Testing Vehicle manufacturers and sports teams now collects millions of data points from wind tunnel runs and testing. These are used in 1000s of calculations per run that typically take hours to process. UDFs will provide them the ability to perform on-demand calculations and adjust parameters in real time.
- Pricing and Risk Calculations Financial institutions are merging more and more sources of data and need to run ever more sophisticated risk management algorithms and return results pre trade. UDFs will enable a next generation risk management platform that will also enable real-time drill-down analytics and on-demand custom XVA library execution.
-
Genomics Signaling Pharma companies utilize genomics data to identify new signals
and to accurately predict drug targets. Data is being ingested into Kinetica, Natural Language
Processing (NLP) will be used to extract specific features and custom UDFs will be called to locate
genome signals.
Read More: InformationWeek : GSK Uses Kinetica for Simulation
Summary
User-defined functions and the orchestration API that enables in-database analytics are available on Kinetica 6.0, available now. Learn more about how to take maximum advantage of GPU accelerated in-database compute by talking with us. Just fill out the form below!