
The Spark connector is typically leveraged to ingest data into Kinetica and perform various transformations in pipeline. A Spark DataFrame is the core type while performing ingestion. Often after a Kinetica table has been created, new fields need to be appended or existing string fields have to be expanded within a Kinetica table. Currently users have to react to these changes and to manually write DDL. With the latest Kinetica Spark connector, users now have a simple approach to handling evolving schemas proactively.
The connector now handles schema changes from a spark DataFrame into a Kinetica table. Specifically, the connector will detect if new columns from a Spark DataFrame and add them to the Kinetica table. Additionally, the connector will also detect if existing Kinetica table strings (charN) columns need to be expanded based on the data in a Spark DataFrame.
Let’s walk through an example. We have a Spark DataFrame and need to ingest data into an existing table in Kinetica named “airline”. The Spark DataFrame has a column SecurityDelay which does not exist in the Kinetica’s airline table. Additionally, the Spark DataFame TailNum column has data which is 10 characters wide which exceeds the current limit (char8) for that field in the airline table. Here is the existing Kinetica airline table metadata.
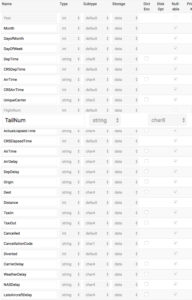
The metadata for the airline table clearly shows the TailNum field is set to char8 and the SecurityDelay field does not exist. During ingest from a Spark DataFrame, the connector will handle adding the new column to the airline table and expanding the TailNum column to handle larger string values.
We won’t go into specific details on how to use the connector as those concepts were well covered in part1 of this blog.
First let’s start a Spark shell, import Kinetica libraries and create a Spark DataFrame.
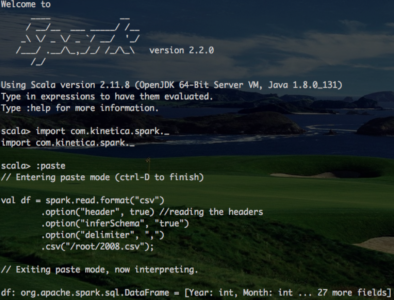
Here is the Spark DataFrame. Notice the new column SecurityDelay. Again, this column does not exist in the Kinetica’s airline table.
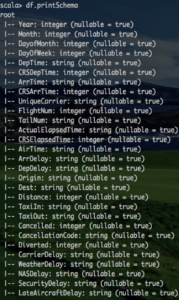
Next a LoaderParams object is created which is standard for the connector. However, notice the new method enableAlter. Calling this method notifies the connector to detect changes between the Spark DataFrame and Kinetica’s table.

Lastly, the ingest is kicked off by calling KineticaWriter.
![]()
The ingest only take a moment. Once the ingest is complete notice the changes which were applied to the airline table in Kinetica. The TailNum field was expanded to char16 to allow for larger values found within the DataFrame. Additionally, the new field SecurityDelay was created and data from the DataFrame for that field was also ingested along with the rest of the DataFrame.
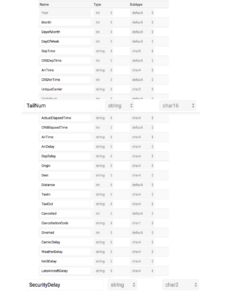
That’s it! The new connector is able to detect and apply changes from a Spark DataFrame to a Kinetica table with ultimate ease of use. A video tutorial will follow shortly, stay tuned!


