AI and Analytics for Real-Time Data






The worlds biggest organizations trust us to solve their hardest problems

The worlds biggest organizations trust us to solve their hardest problems
Speed and Performance at Scale

High-Volume, Real-Time Data Analytics
When milliseconds matter-run complex queries on streaming and historical data instantly.
Learn More
Cross-Domain Analytics at Scale
Combine spatial, time series, graph, vector search, and more in a single query for deep insights.
Learn More
Generative AI for Real-Time Data
Power AI applications with real- time, structured, and unstructured enterprise data.
Learn More
Don't need speed? You likely don't need us.
Kinetica is built to deliver high-speed, complex analytics at scale on modern GPUs and CPUs. If speed isn’t a priority, you likely don’t need us.
Still not sure? Take our quick survey to discover if your business can benefit from Kinetica's cutting-edge performance.
One database, many capabilities

Continuous consumption, unlimited query
Generative AI That Works
Kinetica unlocks all enterprise data - text and tabular - for Generative AI co-pilots and Agentic workflows.
Generative AI That Works
Kinetica unlocks all enterprise data - text and tabular - for Generative AI co-pilots and Agentic workflows.
Leverage both text and tabular data
Use an engine that can retrieve and fuse insights from both text and real-time data to bring operational insights to your fingertips.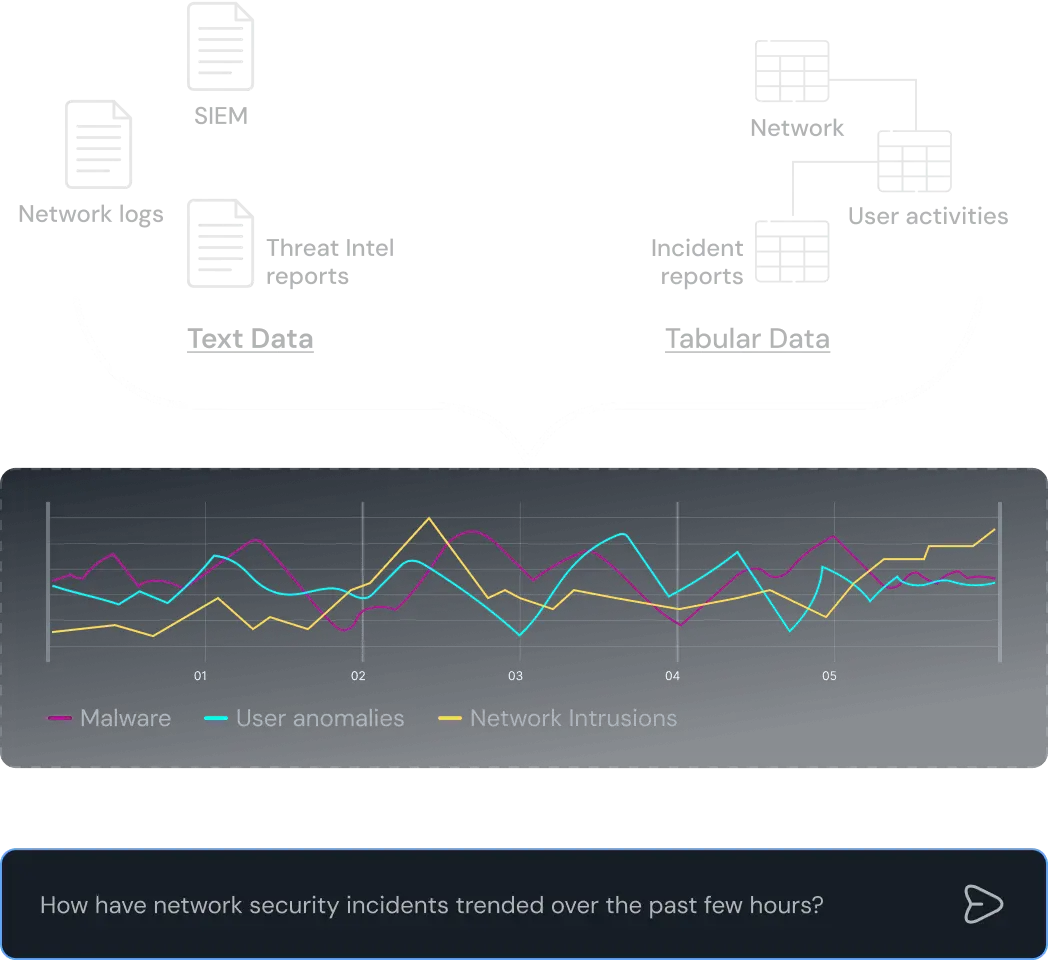
Enterprise-grade security and scale
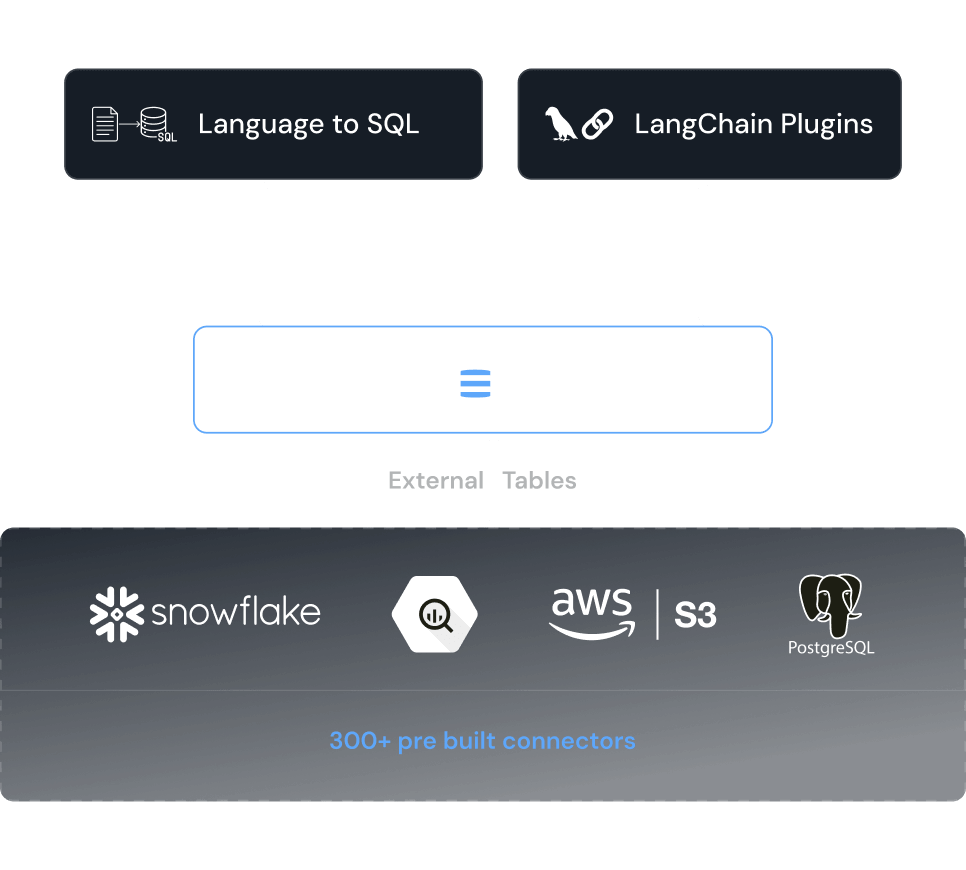
Easily build applications using Kinetica's rich ecosystem of data connectors, Language to SQL features and LangChain plugins.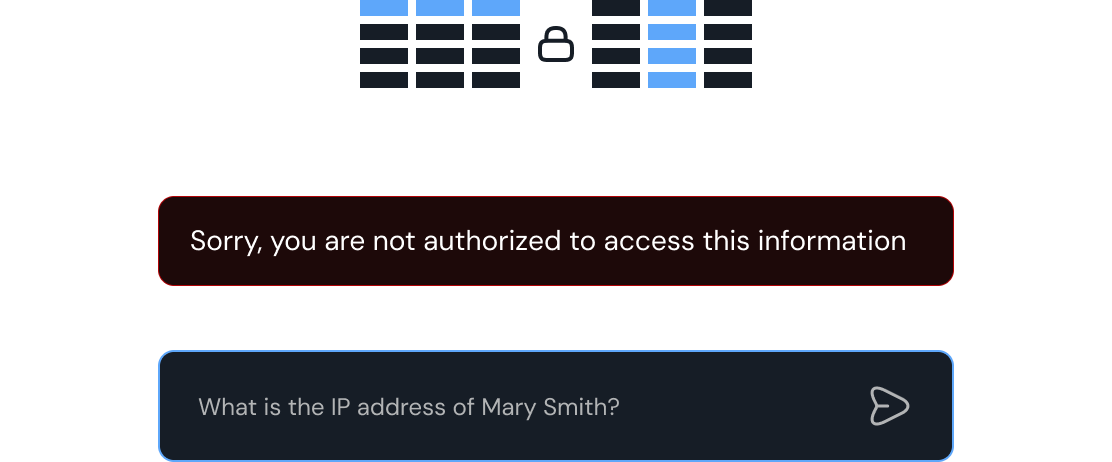
Build in minutes
Harness Kinetica's rich ecosystem of data connectors, Language to SQL features and LangChain plugins to get started now.