Machine Learning and Predictive Analytics in Finance: Observations from the Field
Financial institutions have long been on the cutting edge of quantitative analytics. Trade decisioning, risk calculations, and fraud prevention are all now heavily driven by data. But as the volume of data has grown, as analysis has become ever more sophisticated, and as pressure builds for timely results, computation is more and more of a challenge. Increasingly computer scientists and engineers are being called on to tackle problems of scale and complexity common in finance.
Machine learning offers new opportunities, such as to inform trade decisions made throughout the day or for more advanced risk calculations. The problem, however, is that massive compute resources and advanced data science libraries are required to take advantage of this paradigm. This inherently prevents organizations from expanding this area of the business to the scale they would like.
How can financial services organizations get to the point where predictive models, optimized through machine learning, are made available to business users? – ideally with the up-to-the-moment data and sub-second response?
Over the past year, in discussions with a wide variety of financial institutions, we’ve seen common challenges – and fortunately, a clear solution:
GPUs solve for increasing compute; difficulties remain
Graphics Processing Units (GPUs) are now widely recognized as the way forward for increasing compute power. With thousands of processing cores capable of crunching large volumes of data in parallel, they are far more capable than CPUs at the types of complex calculations required of financial analytics.
Portfolio risk calculations are one example where GPUs are proving value. With large datasets and mathematically intensive calculations, risk scores have typically been calculated overnight in batch. This slow turnaround makes it difficult to adapt to market changes in real time. GPUs make it possible for these same large risk aggregations to be calculated on Kinetica in under a second, where previously it might have taken hours.
New opportunities abound to incorporate unstructured data like online content, or semi-structured data such as company reports, to identify larger patterns and build new models. But such analysis and modeling requires more advanced programming and new libraries. Whereas quants might typically reach for out of the box statistical models using packages such as R, data heavy analytics and machine learning calls might call for tools such as C++ or python, using new libraries such as Tensorflow, Caffe, or BIDMach.
GPUs excel at the types operations needed to infer signals and make predictions from massive volumes of data. To take advantage of these new tools, data typically needed to be moved into specialized environments. But, once moved onto a specialized system, the next question is how can the benefits of this new technology be made available to line of business decision makers?
Data engineering teams are struggling to deploy AI to the business
This process of deploying predictive models to the business lies on the shoulders of the data and technology teams. They are faced with an ever-growing ecosystem of tools and technologies, most of which are not ready for the performance and scalability demands of production use.
How do you synchronize the data-science environment to get up to the minute data? How do you make models easy to run and use? How do you enable decision makers to adjust parameters without the help of computational engineers? These are just a few of the questions that the big data team has to answer.
For example, portfolio managers want the ability to adjust parameters on their portfolios and kick off risk calculations in real time. Normal tasks, such as running filters on various stock symbols or adjusting time periods to understand historical performance, often need to be sent back to the technical team. This inherently slows down the ability to understand risk scores for a particular portfolio.
Kinetica: A single platform for AI and BI demands
What if data exploration, model scoring, and model consumption could all be performed on a single compute-enhanced platform? A platform that would enable business users to perform complex risk management and trading decision queries on demand without needing to call on others to model data on separate systems?
This is now possible with Kinetica – a GPU-accelerated, distributed, in-memory database. Kinetica is able to draw on the parallel processing power of the GPU for ridiculously fast data processing. Kinetica’s user-defined function API makes it possible for advanced machine learning on the same data platform as used for more traditional analytics.
Operational data can now be connected to models built with machine learning libraries that require the performance and parallelization benefits of the GPU. This all works on a system that uses common database paradigms, and one that is viable for operational analytics workloads.
The beauty comes when cutting-edge models are brought together with trade decisions on the same system. Quants can easily make models available to traders through Kinetica’s user-defined functions API. Risk algorithms, such as Monte Carlo methods, can be made directly available to traders through the analytics tools already on their desks.
A simple example of such= algorithms being run in-database is with this example using Reveal, Kinetica’s visualization framework. Here a relatively simple risk calculation is made available as a user-defined function – the same manner in which analysts could get access to more computationally sophisticated analysis.
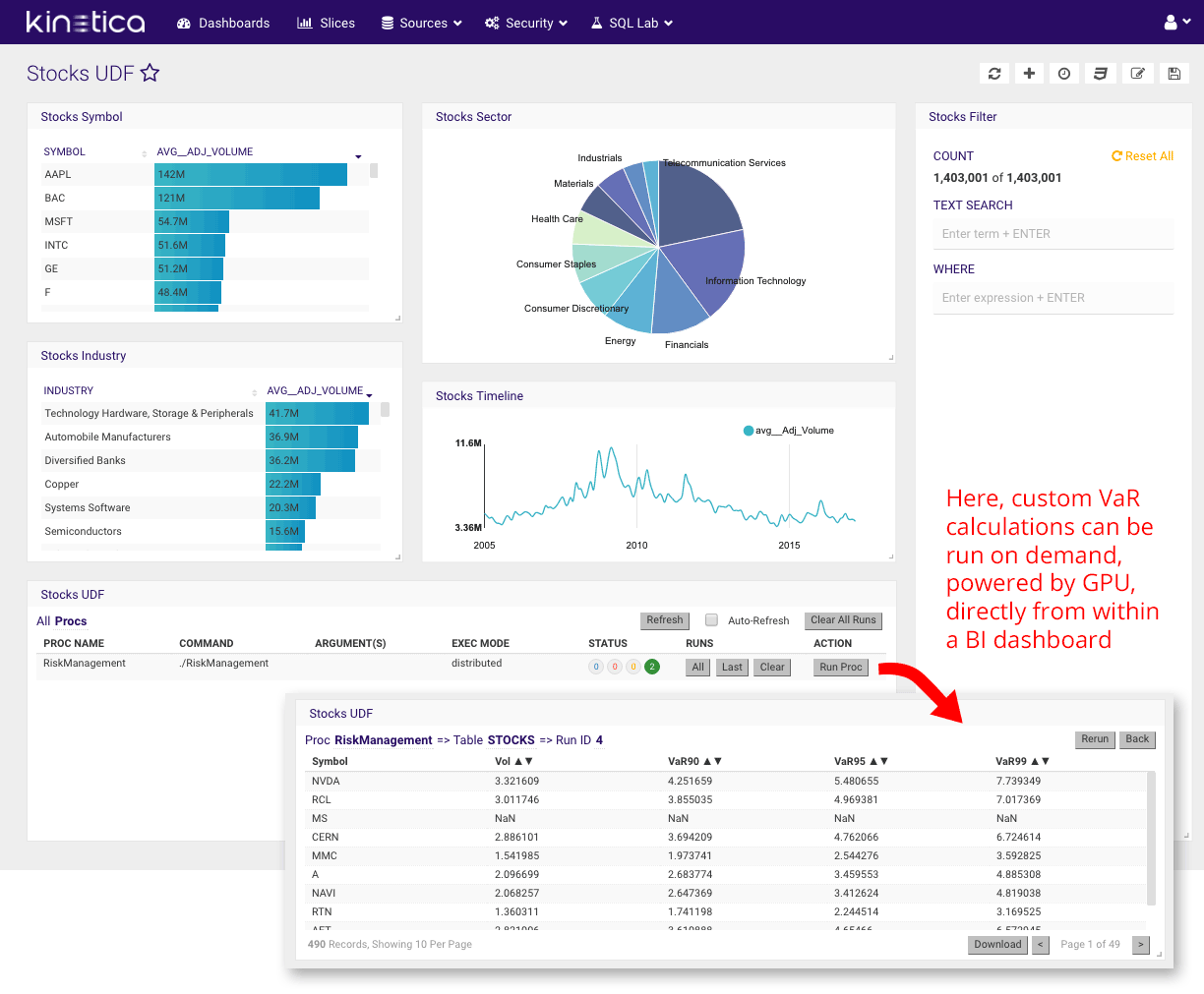
Try the demo out for yourself, with the Kinetica Risk Demo.
Kinetica provides a bridge to bring advanced analytics and machine learning into financial analysis. With this new paradigm, finance companies can manage risk interactively—delivering the ability to make smarter and better decisions on trades – and that’s something you can take to the bank!
Making Sense of Sensor Data

Very interesting…Kinetica on an IBM POWER Minsky are unbeatable…