
The problem is widely felt. As data collection has mushroomed, traditional data systems struggle to produce timely alerts to problems and other real time events. Financial organizations want to be able to spot fraud, or maintain a running tallies of risk and exposure. Tracking systems need to flag when vehicles leave pre-determined paths or allow interactive analysis on millions of objects. This type of speed would enables businesses to respond to opportunities and threats as they unfold rather than after they do.
But data warehouses might take minutes, hours, and sometimes even days to run queries on large and changing datasets. Stream processing systems are too simple to provide context on the data. How do you get to low latency and high performance analytics at scale in seconds or even milliseconds.
First, let's look at some history:
From Batch to Streaming Analytics
The early 2000's saw a shift away from centralized data systems to a distributed model. These new NoSQL database systems could store vast amounts of data distributed across cheap commodity computers thereby lowering the cost of owning and analyzing massive amounts of data.
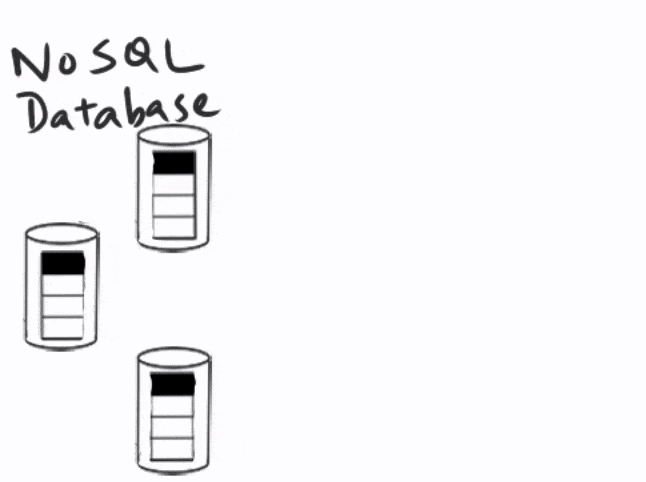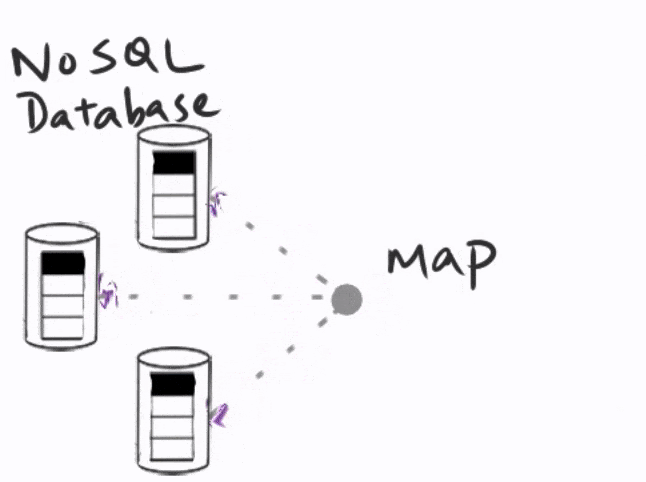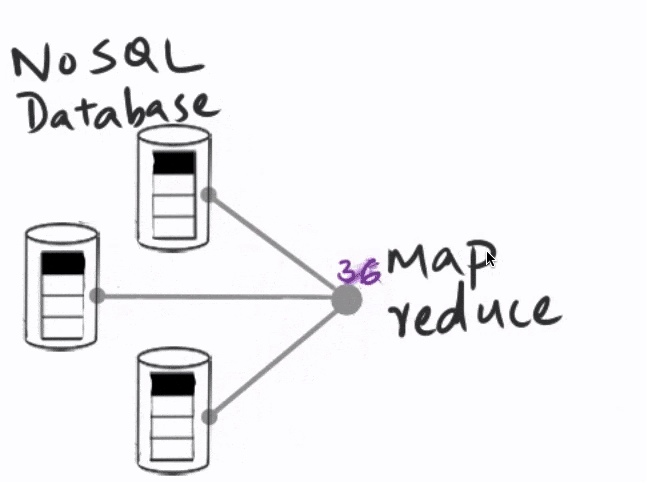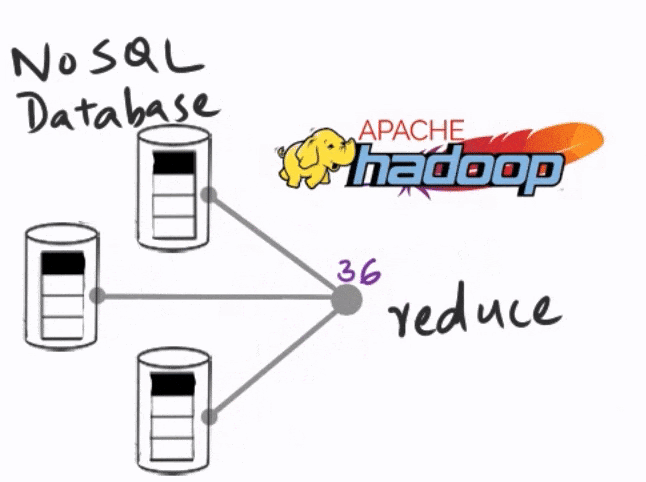
In a typical distributed system, users would write queries, which would then be mapped to the individual nodes that carry a part of the data. The intermediate results from each of these nodes would then be reduced to get the final result.
Apache Hadoop, the open source project that came out of Google research, laid most of the groundwork for this. The majority of solutions that currently exist are based on the MapReduce and batch processing concepts introduced by Hadoop in the mid-2000s. This is the current dominant paradigm in database technologies. So let's take a closer look at a typical batch processing workflow.
Imagine you are a company that produces three types of products represented by these three different shapes below. You store your data using the Hadoop Distributed File System (HDFS). You are interested in identifying product anomalies that are represented by the color yellow.
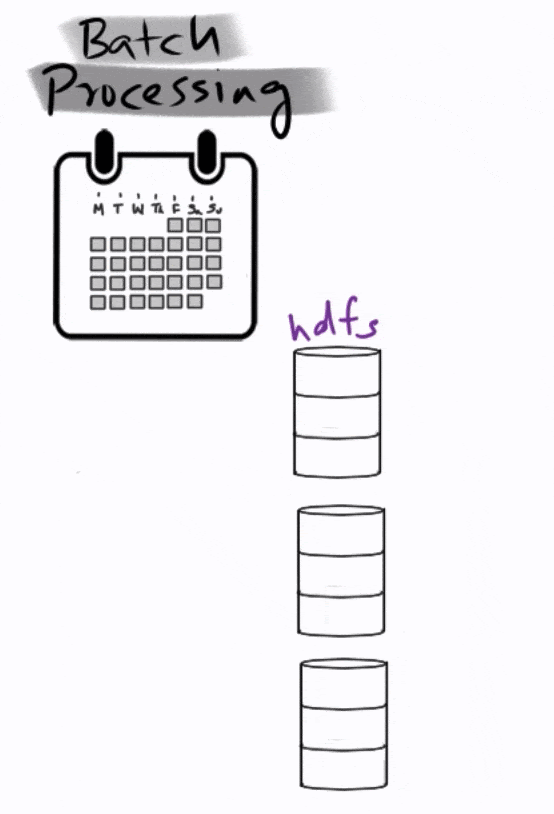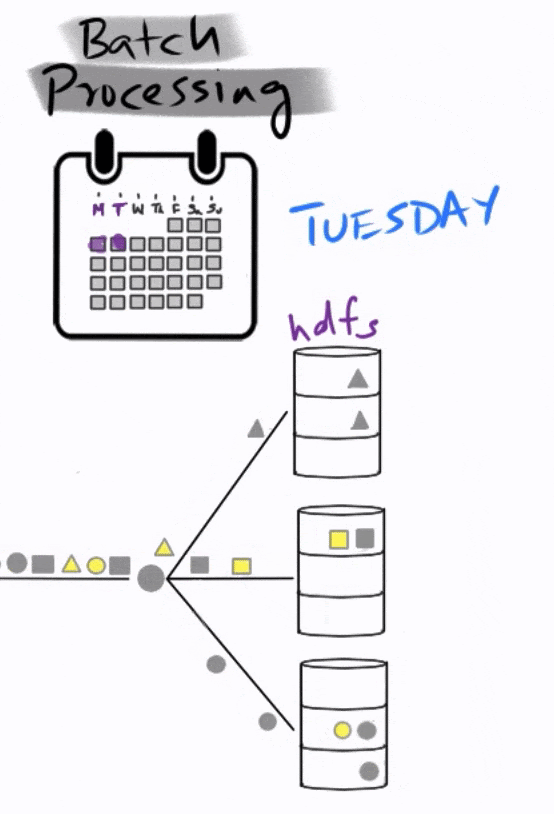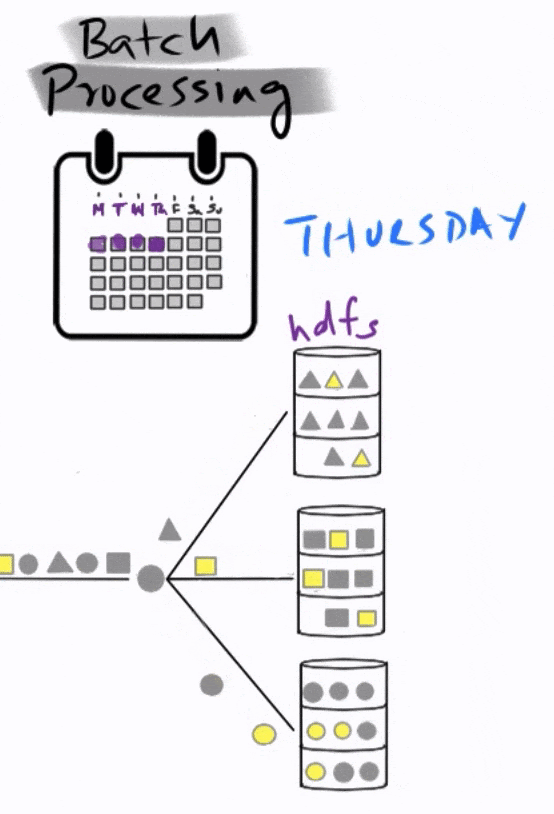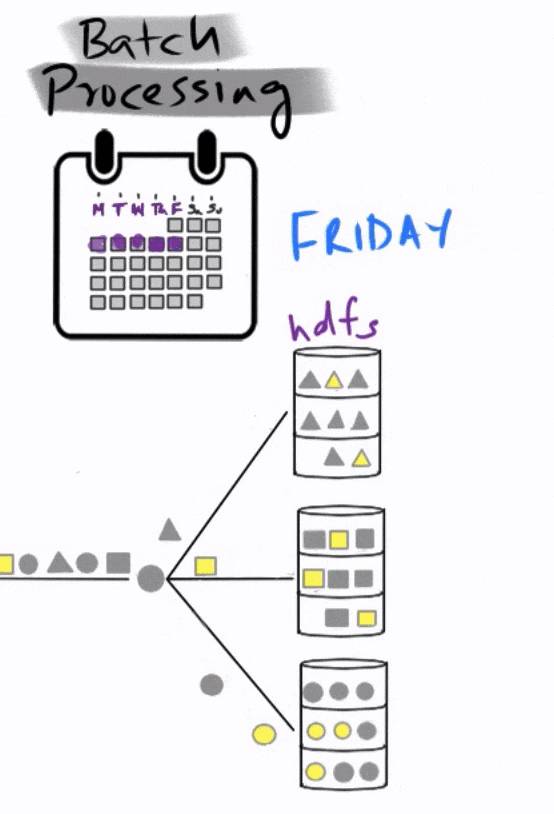
You start collecting data on Monday until the end of the week on Friday.
At the end of the day on Friday, the analytics team fires off a scheduled MapReduce job that identifies anomalies. This is a complicated piece of code that is mapped to the different data partitions in order to identify anomalies, and then reduced to find the final total, which then goes into a report that is submitted on Monday.
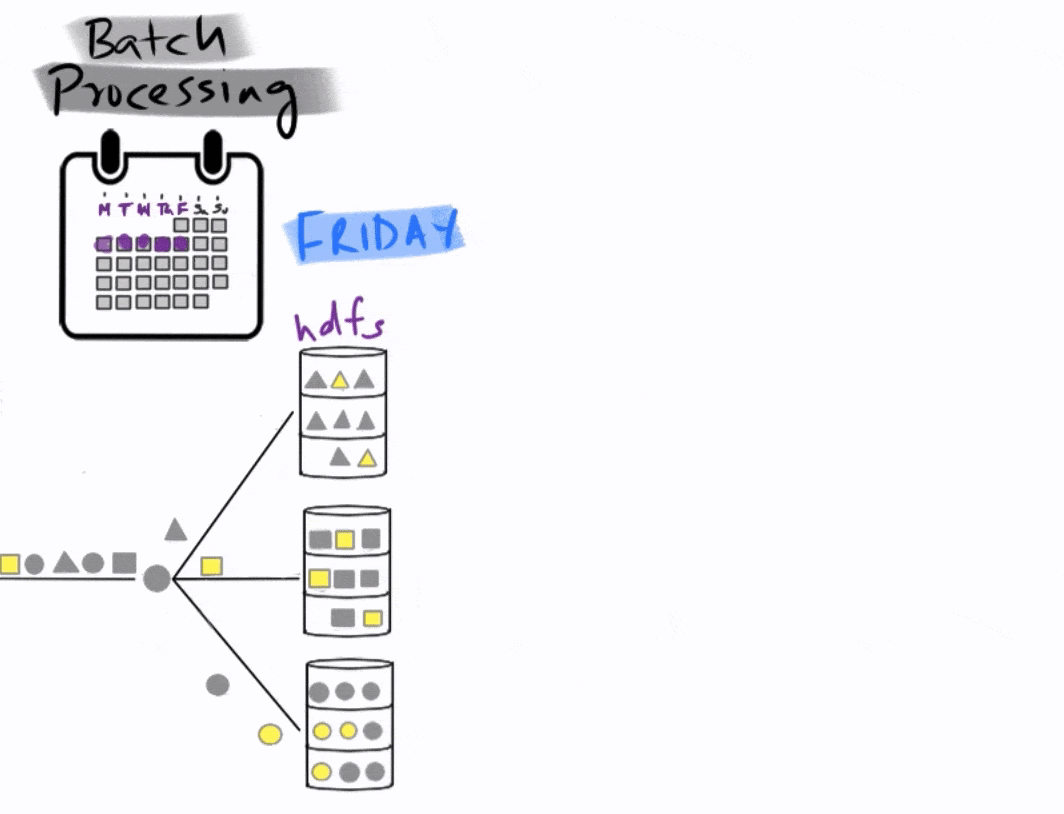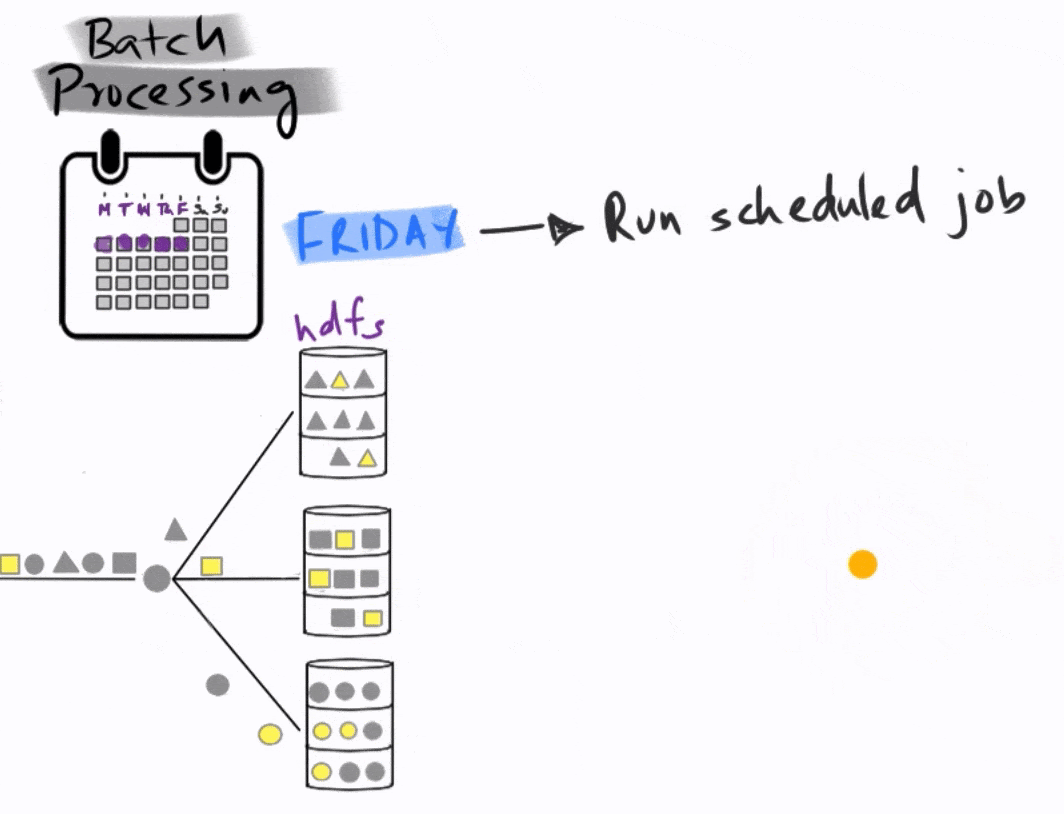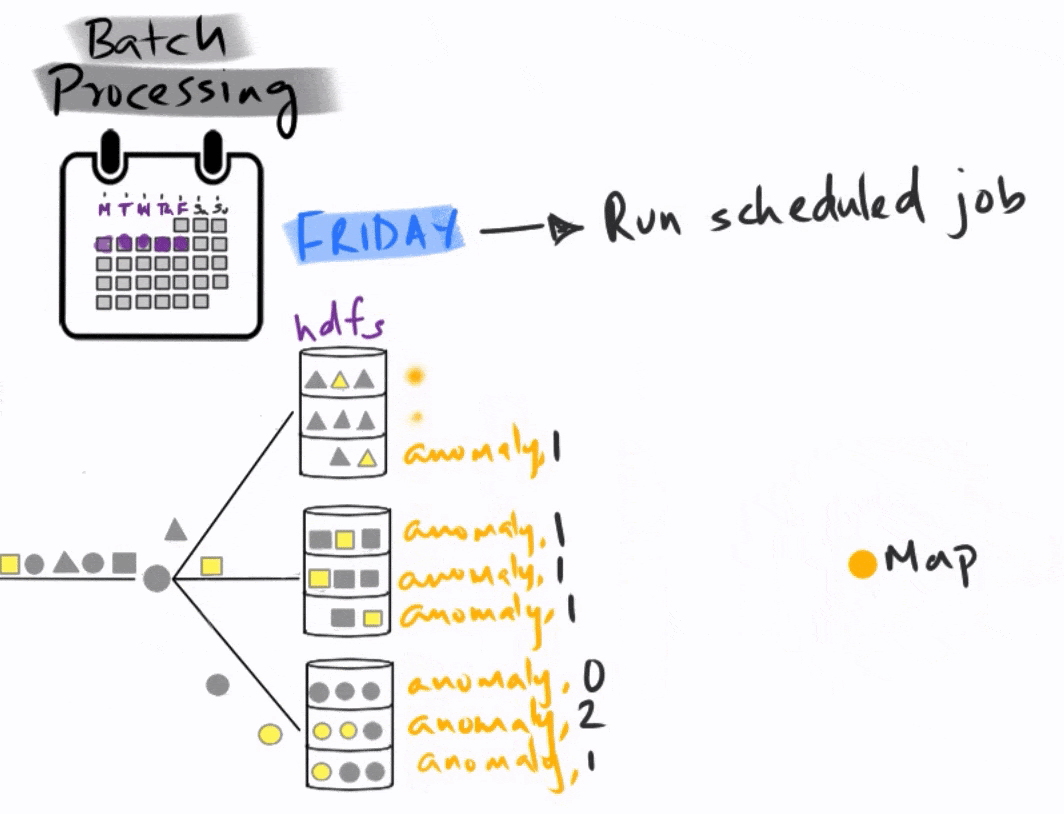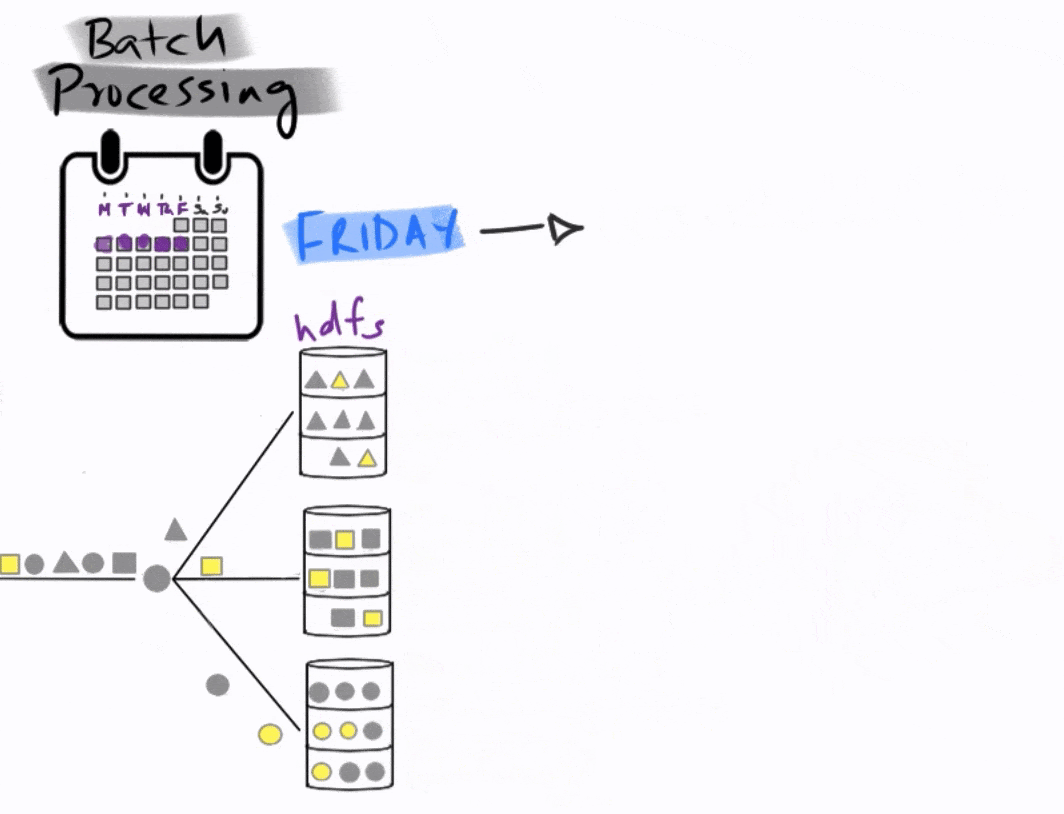
This is a typical batch processing workflow, where the data is collected and analyzed in batches, long after the events of interest have occurred.
This approach was a remarkable success when initially proposed in the mid 2000s, particularly given its ability to handle the massive amounts of data generated as the internet expanded. But the world has since moved on.
Today we produce a tremendous amount of streaming data ranging from click events to IoT devices, from telemetry to geospatial services, and more. The last two years alone have generated 90% of all the data that exists today. This pace will only increase as more devices and more people are connected.
While new solutions like Apache Kafka allow us to capture these massive streams of data, the analysis of this data still relies on the now old paradigm of batch processing.
The biggest drawback of this approach is that every second wasted after an event has occurred represents money and competitive advantage lost. For instance, in our example, we would have liked to identify the anomalies as they were occurring, rather than days after they did.
The best solutions today can cut this delay down from a week to perhaps a day or even half a day. And they have to rely on a patchwork of tools and infrastructure to accomplish this. Even after disregarding the cost and complexity of achieving this, the delay is simply too long.
Trying to apply batch processing to handle streaming analytics can often feel like you are trying to jam a square peg into a round hole. And it is no surprise that enterprises often get stuck when conventional solutions reach their breaking point.
Kinetica: Streaming Analytics at Scale
Kinetica is a real-time database that can is designed to run complex queries on millions of rows of streaming data…in real time. Solving these sorts of streaming analytical challenges is something that Kinetica can handle with ease.
So what is the secret?
The key to Kinetica's computation speed and power is that it has been vectorized from scratch to harness the capabilities of modern hardware.
Vectorization quite simply is the ability to apply the same instruction on multiple pieces of data simultaneously.
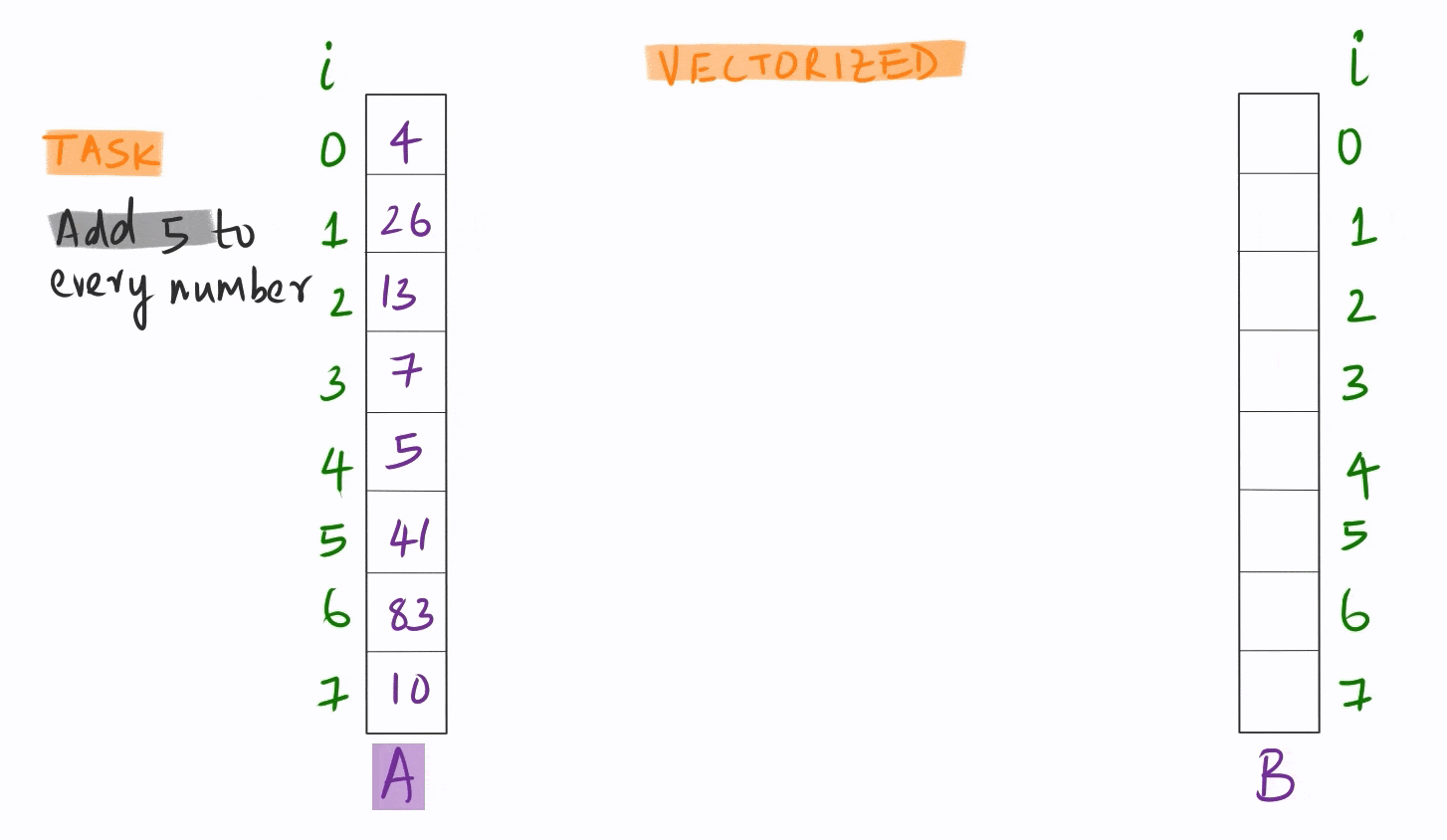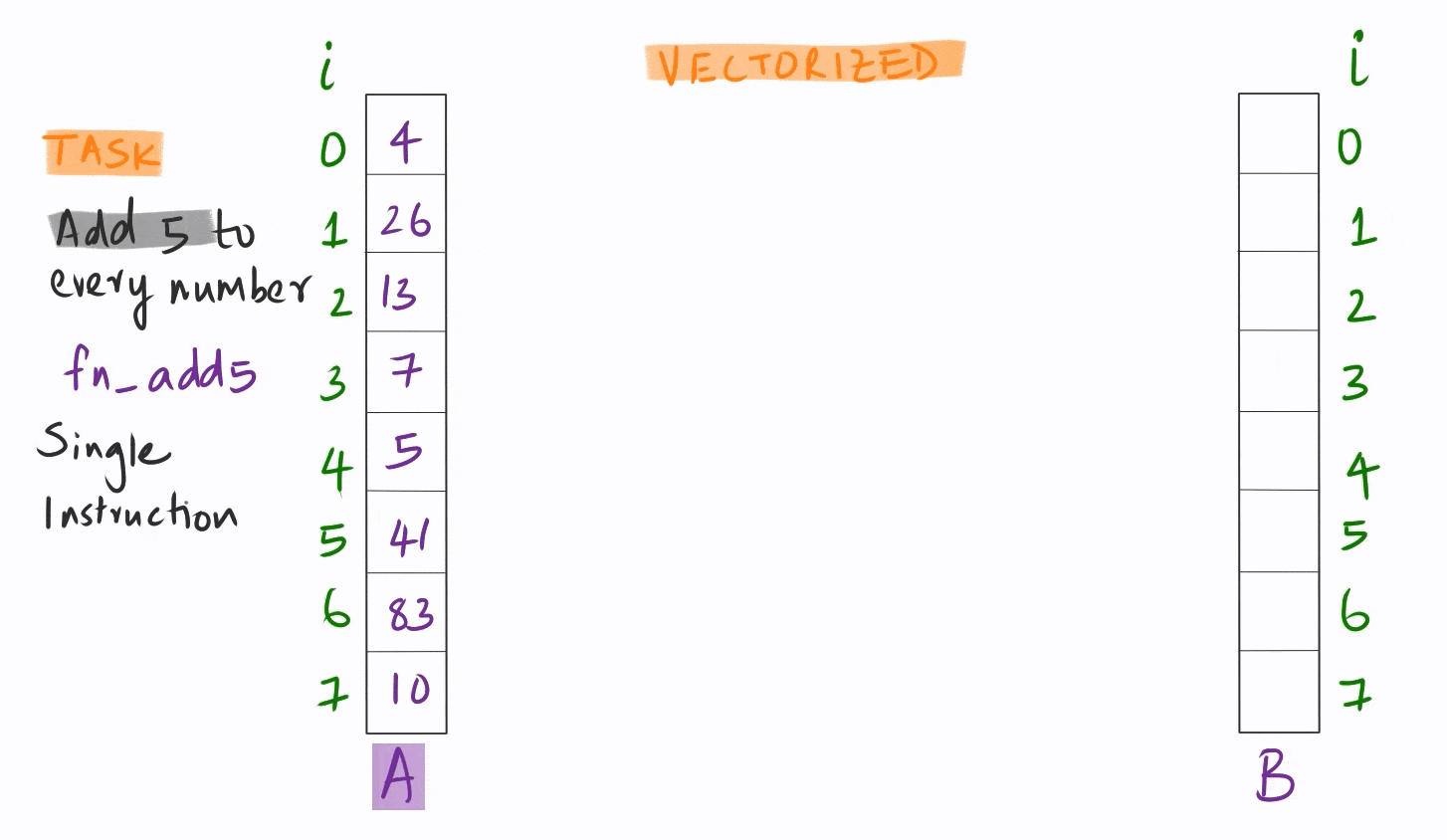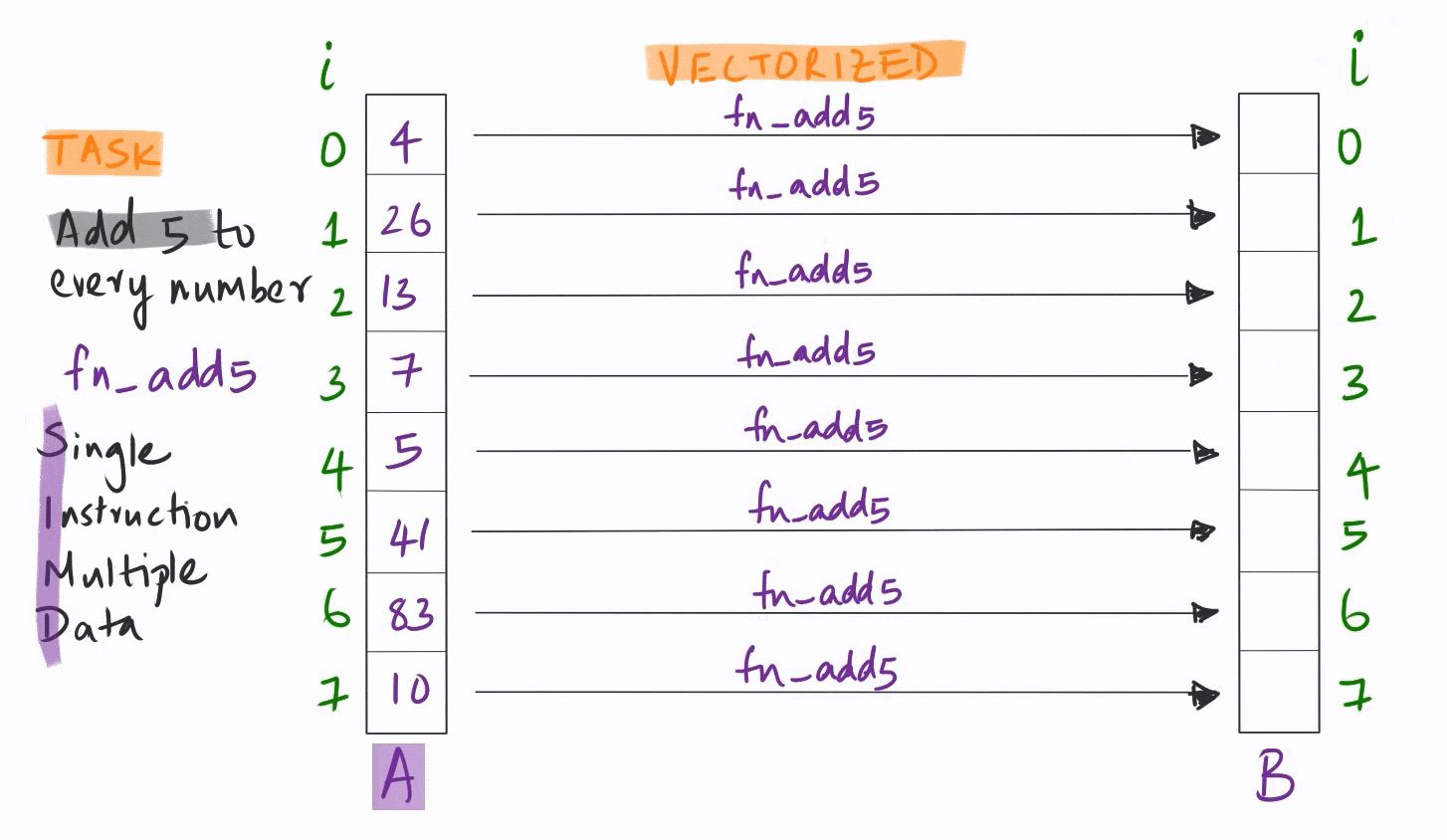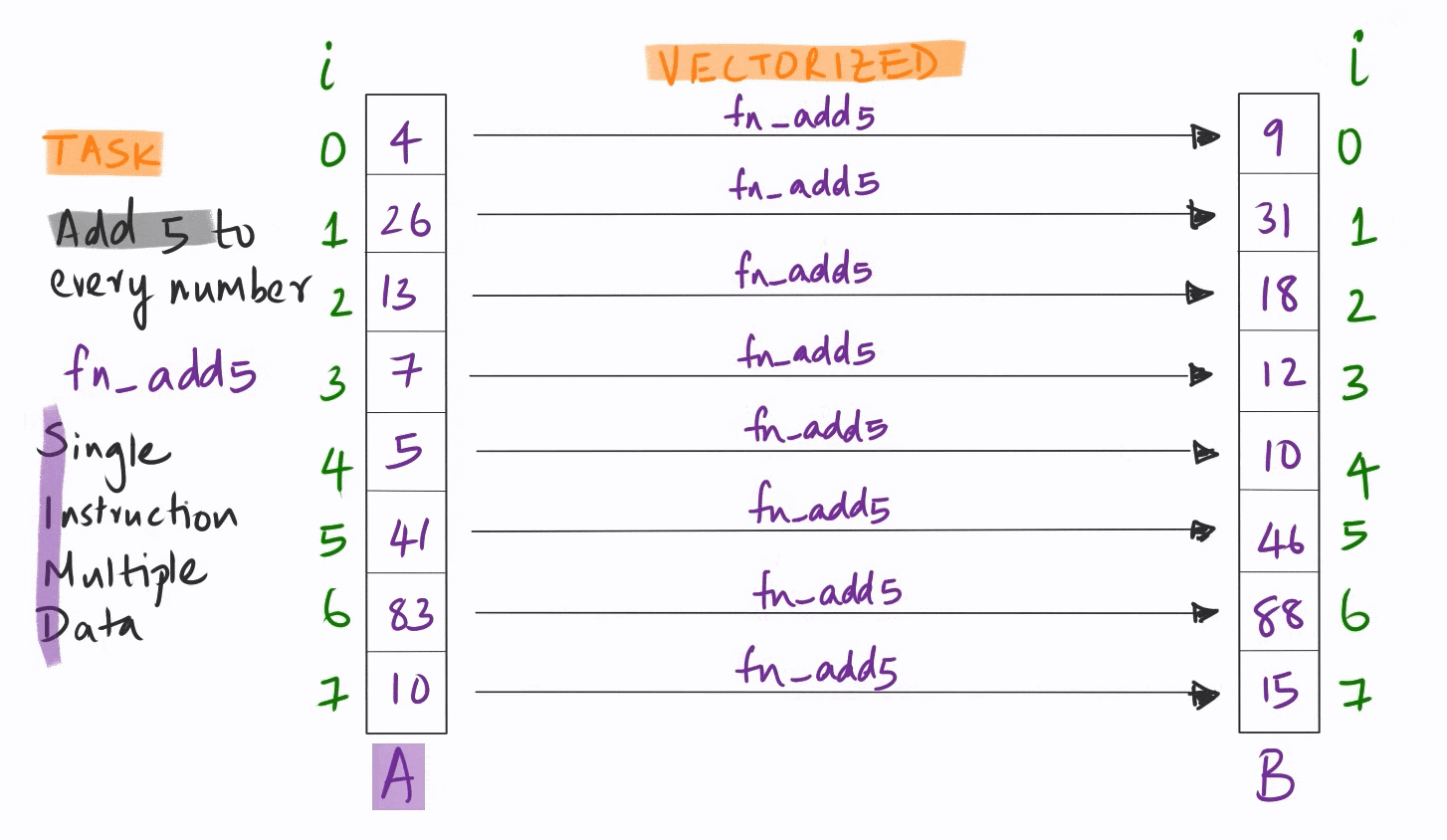
This is orders of magnitude faster than the conventional sequential model where each piece of data is handled one after another in sequence.
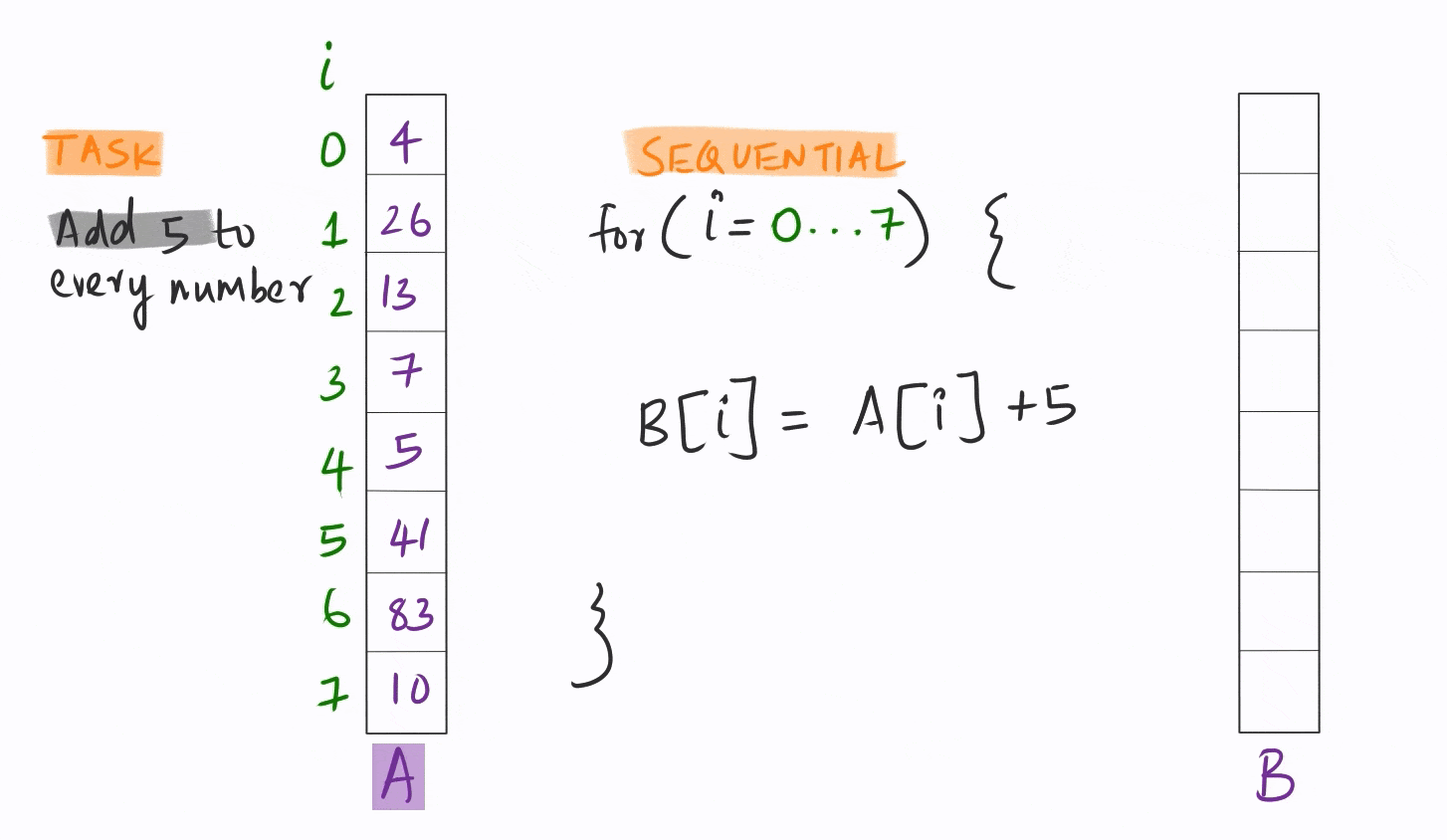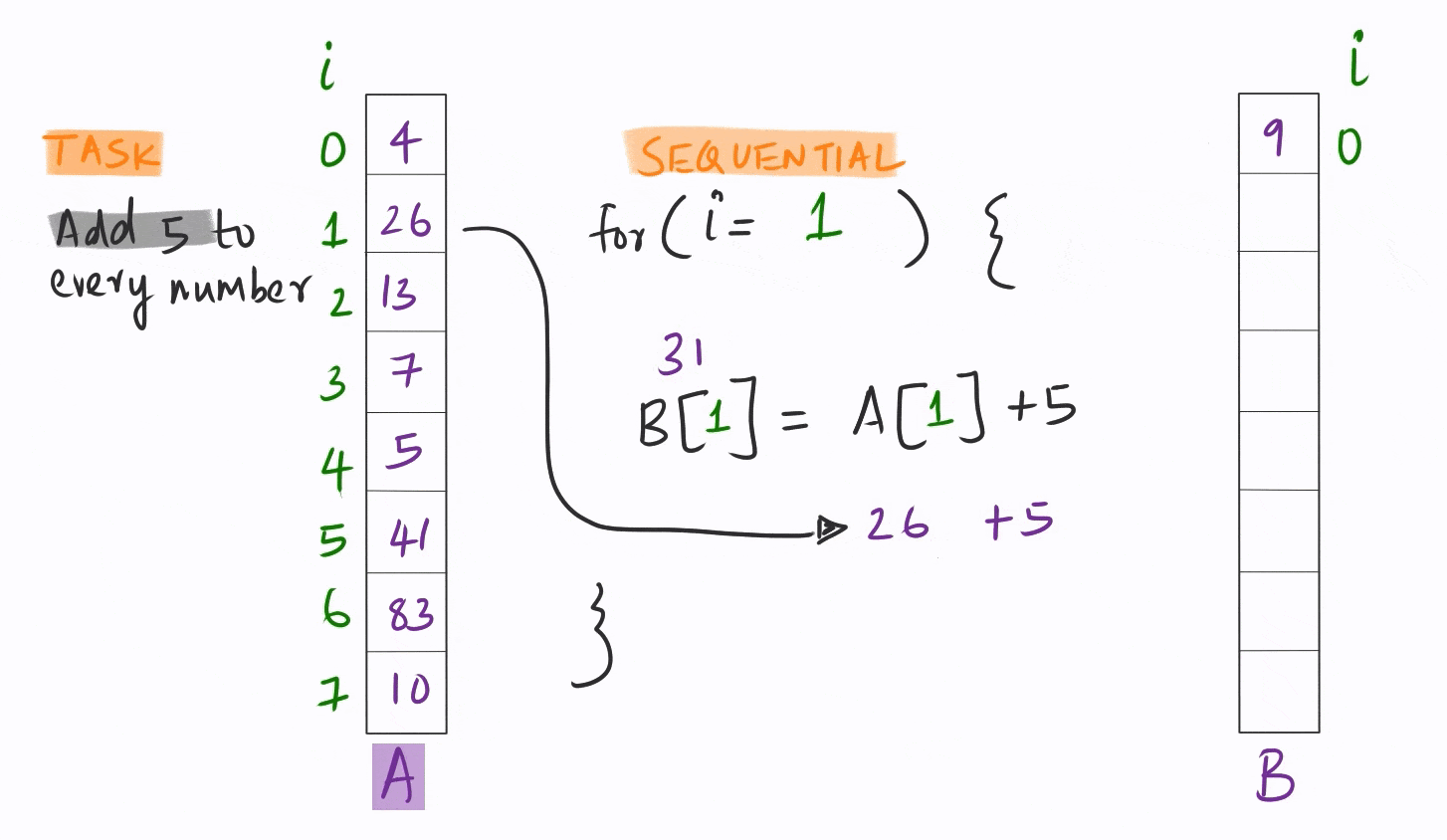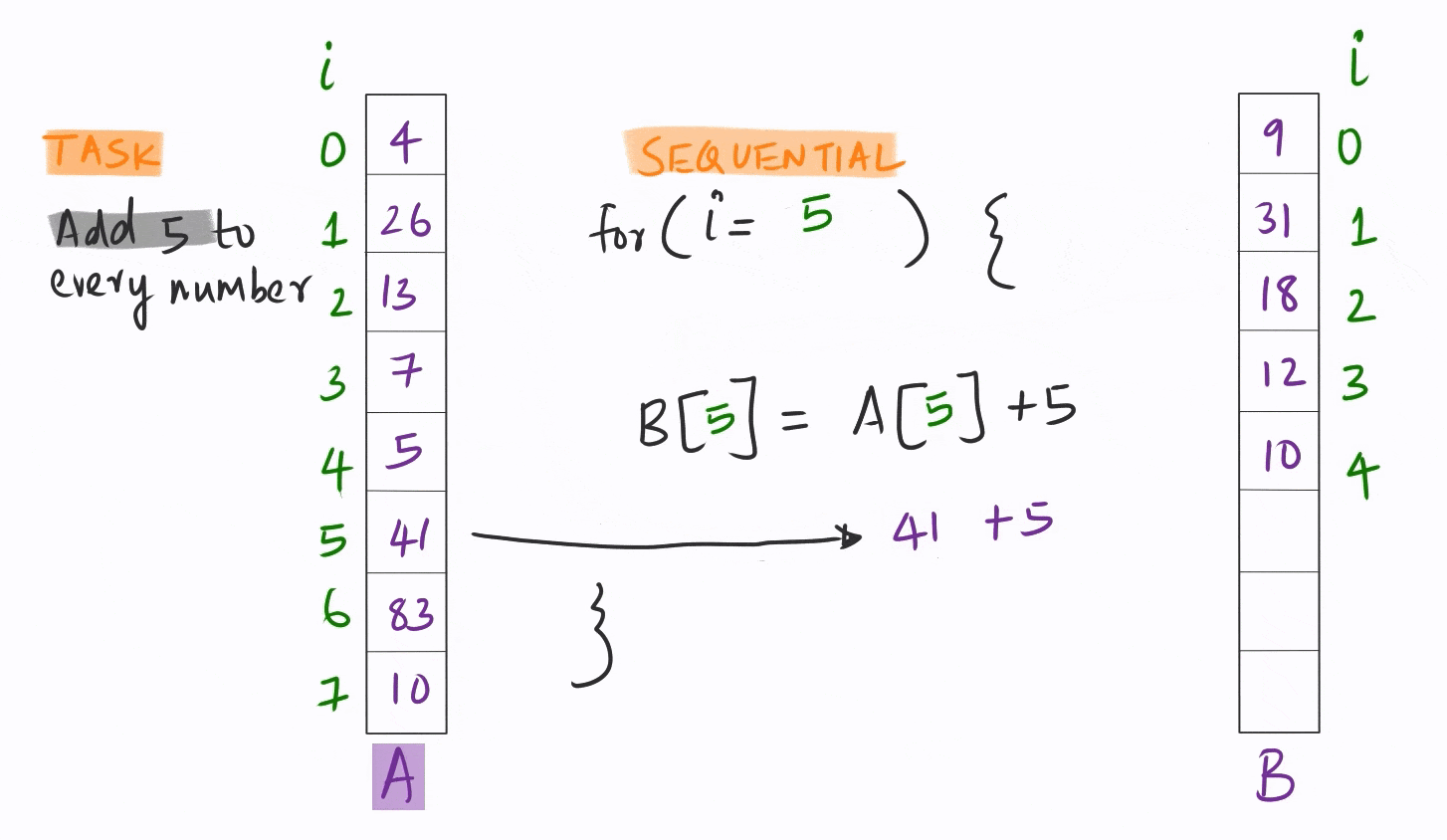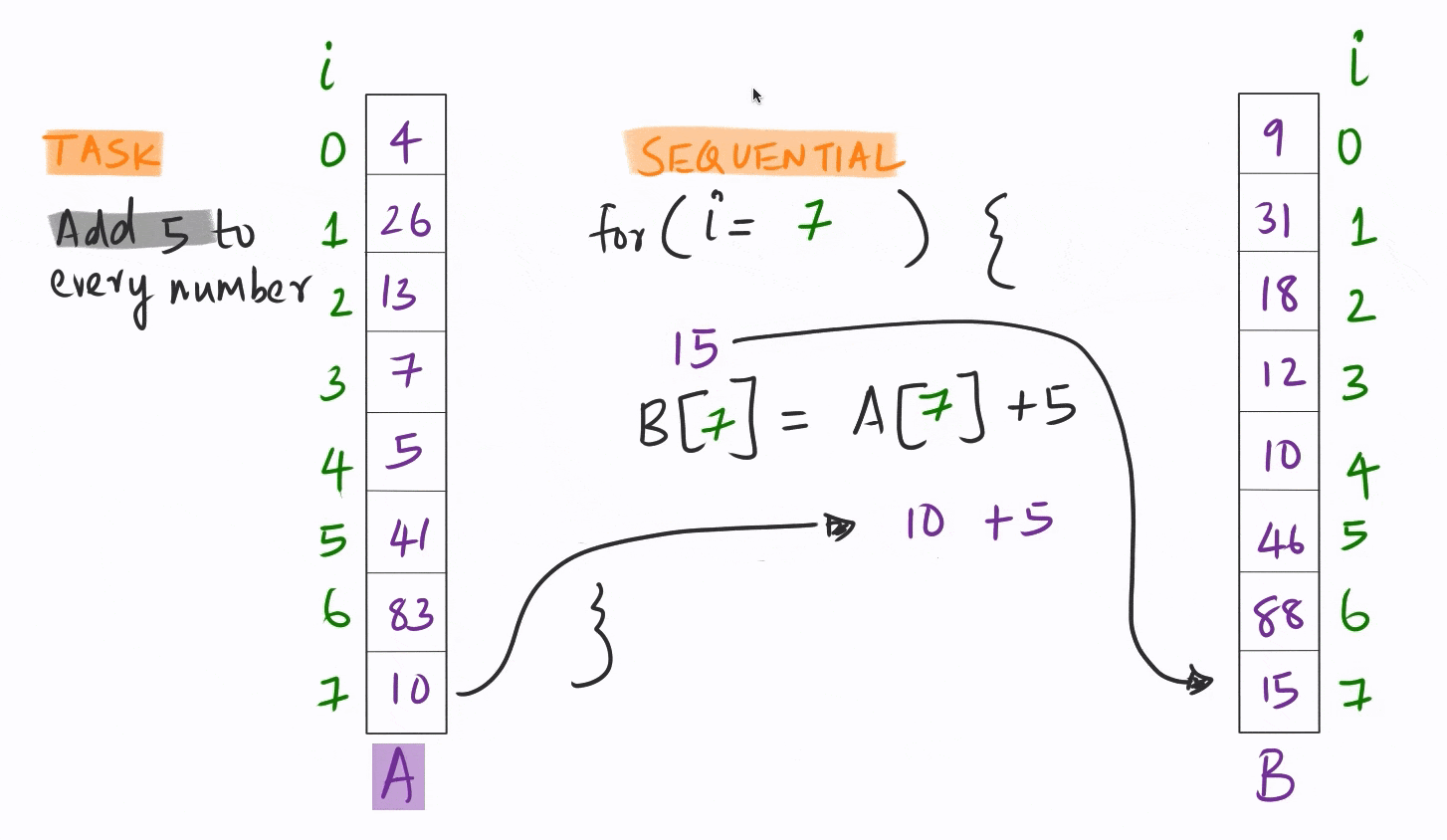
Most of the analytical code out there is written in this sequential mode. This is understandable, since until about a decade ago, CPU and GPU hardware could not really support vectorization for data analysis.
Analytical functions in Kinetica on the other hand have been written from scratch to make use of the vectorization capabilities of modern hardware. And the great thing about Kinetica is that you don't have to write a single piece of vectorized code yourself. You can simply write your queries in data science languages that you are familiar with, and under the hood Kinetica will deliver your results at mind boggling speeds.
While vectorization on its own can deliver blazing fast computational performance, there's more to it. Kinetica adds additional layers of features for speed and performance, such as a memory first approach that prioritizes the use of faster system memory and the VRAM, which is chip memory that is co-located with the GPU, a proprietary columnar data storage format, and intelligent data distribution and localization features that minimize the movement of data between nodes in a cluster.
Finally, Kinetica's integrated analytical suite, which have all been written from scratch ensures that we can harness Kinetica's amazing capabilities and perform all our computational tasks in-house without having to bring in external solutions.
Technologies like Kinetica represent the next generation of event driven database technologies built for modern hardware that can respond to events as they occur rather than after they do. And it accomplishes all of this at lower cost and complexity.
Hari Subhash is Sr. Manager of Technical Training and Enablement at Kinetica.