
What is Real-Time Data Streaming?
Businesses used to expect their data to arrive in batches, made available for analysis after the fact. But now, people use digital devices that generate data available in real time, and many machines and devices generate data of their own volition. Data received in real time is referred to as streaming data, because it flows in as it is created. Businesses that respond to this real-time data streaming have a competitive advantage, anticipating customer needs in the now, instead of developing insights about them to use later.
In this age of digital innovation, organizations need to have continuous insight into data about their services, users, and the resources powering these services so they can act in the moment. They must be able to analyze as fast as data streams. There are three major benefits to doing this:
1. Leveraging the IoT real-time data streaming
Wireless networks have made it possible for an ever-growing cadre of devices, from smart phones to cars, refrigerators to home security systems, to send and receive data over the network instantaneously: this is the internet of things (IoT) at work. Organizations that react to valuable information streaming in from these IoT devices in real time can respond to customer needs in the moment, while competitors that analyze after the fact miss opportunities.
2. Tapping into real-time streaming big data
Process large-scale queries with thousands of messages per second flowing in, and join with billions of records on the fly. Real-time streaming big data volume used to make analysis unwieldy, but now you can incorporate hundreds of data feeds to assess and take action immediately.
3. Get instant insight from your real-time data streaming analytics
Analyze streaming and historical data at high volume and velocity with zero latency. This paints a real-time picture that takes the entire profile of the customer or situation into account–and gives the organization the information to respond effectively and in the moment, meeting and exceeding expectations.
Real-Time Data Streaming Analytics with Kinetica
While real-time data streaming processing platforms like Kafka stream data at high speed, a real-time database further provides the ability to do advanced analytics on the streaming data by combining one or more streams. Let's explore how Kinetica delivers high-performance and real-time analytics on streaming data at massive scale to today's organizations.
Kinetica helps its customers solve a variety of problems, including dynamic inventory replenishment, mail routing optimization, shortening oil and gas discovery time, scalable ocean trash detection for environmental improvement programs, faster new drug discovery, and many more. While these use cases are in different industries and domains, there is one common theme behind them — real-time data streaming pipelines with high throughput streaming ingestion while carrying out high performance, real-time data streaming analytics at the same time.
To give you a better idea of the scale, consider the details of these two Kinetica real-time data streaming examples of customers' use cases:
- A retailer ingests 250 million records per day for inventory tracking on an 8-node Tesla P100 Kinetica cluster while performing 112,000 read queries per second.
- A large mail carrier ingests a billion events per day for mail routing optimization on a 10-node P100 Kinetica cluster, while 15,000 users are simultaneously querying the data.
Kinetica's blazingly fast real-time data streaming architecture is made possible by its native parallel ingest and optimized non-blocking data structures. Kinetica is a distributed massively parallel platform — there are multiple servers working simultaneously on distributed data. To distribute a table across many servers, Kinetica uses a special key called a shard_key that dictates the partitioning. Once a sharding scheme has been defined, data can be ingested either sequentially at head node, or in parallel by worker nodes for maximum throughput.
Sequential Ingest
When data is ingested sequentially, an application sends batches of data serially to Kinetica's head node, which will forward the data to the appropriate worker based on shard_key.
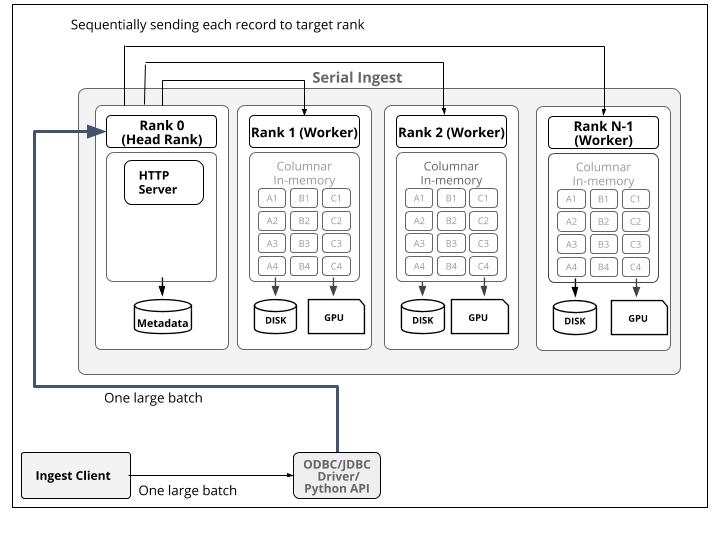
However, this means the head node can become a bottleneck for ingesting data.
Let us look at the example code for sequential ingest:
# Establish connection with a locally-running instance of Kinetica
h_db = gpudb.GPUdb(
encoding="BINARY",
host="127.0.0.1",
port="9191",
username="user1",
password="mysecret"
)
collection = "taxi_info"
table_taxi = "taxi_trip_data"
# create collection
collection_option_object = gpudb.GPUdbTableOptions.default().collection_name(collection)
# Define table columns
taxi_columns = [
["transaction_id", "long", "primary_key"],
["payment_id", "long", "primary_key", "shard_key"],
["vendor_id", "string", "char4"],
["pickup_datetime", "long", "timestamp"],
["dropoff_datetime", "long", "timestamp"],
["passenger_count", "int", "int8"],
["trip_distance", "float"],
["pickup_longitude", "float"],
["pickup_latitude", "float"],
["dropoff_longitude", "float"],
["dropoff_latitude", "float"]
]
# Clear any existing table with the same name
h_db.clear_table(table_name=table_taxi, options=no_error_option)
# Create the table from the type and place it in a collection
try:
table_taxi_obj = gpudb.GPUdbTable(
_type=taxi_columns,
name=table_taxi,
options=collection_option_object,
db=h_db
)
print "Taxi table object successfully created"
except gpudb.GPUdbException as e:
print "Taxi table object creation failure: {}".format(str(e))
print "n"
print "INSERTING DATA"
print "--------------"
print
# Insert records from a CSV File into the Taxi table
print "Inserting records into the Taxi table via CSV..."
print
taxi_data = csv.reader(open('/tmp/data/taxi_trip_data.csv'))
taxi_data.next()
taxi_records = []
for record in taxi_data:
record_data = []
record_data.append(long(record))
record_data.append(long(record))
record_data.append(record)
record_data.append(long(record))
record_data.append(long(record))
record_data.append(int(record))
record_data.append(float(record))
record_data.append(float(record))
record_data.append(float(record))
record_data.append(float(record))
record_data.append(float(record))
taxi_records.append(record_data)
table_taxi_obj.insert_records(taxi_records)
print "Number of records inserted into the Taxi table: {}".format(
table_taxi_obj.size()
)
Parallel Ingest
To avoid a bottleneck at the head node, the application can instead choose to tell Kinetica's Python, ODBC, or JDBC driver that the data should be ingested in parallel by all the worker nodes. By simply flipping a switch, Kinetica is able to divvy the data client-side before sending it to the designated worker node, which streamlines communication and processing time.
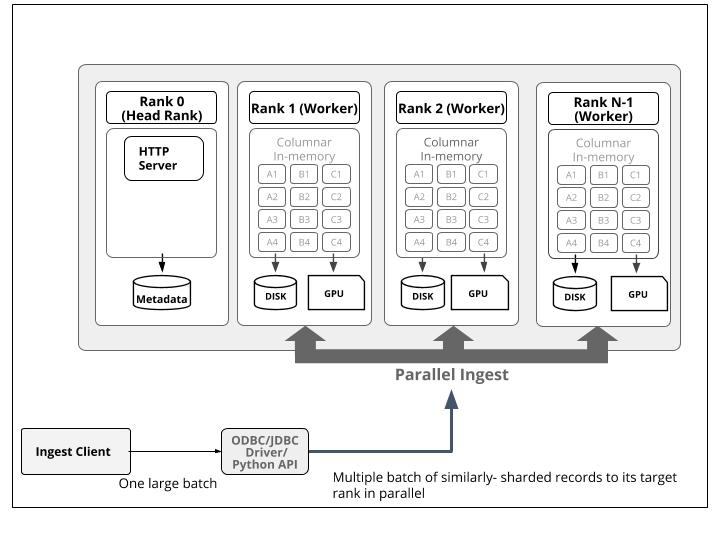
Now, let us look at the example code for doing parallel ingest:
# Establish connection with a locally-running instance of Kinetica
h_db = gpudb.GPUdb(
encoding="BINARY",
host="127.0.0.1",
port="9191",
username="user1",
password="mysecret"
)
collection = "taxi_info"
table_taxi = "taxi_trip_data"
# create collection
collection_option_object = gpudb.GPUdbTableOptions.default().collection_name(collection)
# Define table columns
taxi_columns = [
["transaction_id", "long", "primary_key"],
["payment_id", "long", "primary_key", "shard_key"],
["vendor_id", "string", "char4"],
["pickup_datetime", "long", "timestamp"],
["dropoff_datetime", "long", "timestamp"],
["passenger_count", "int", "int8"],
["trip_distance", "float"],
["pickup_longitude", "float"],
["pickup_latitude", "float"],
["dropoff_longitude", "float"],
["dropoff_latitude", "float"]
]
# Clear any existing table with the same name
h_db.clear_table(table_name=table_taxi, options=no_error_option)
# Create the table from the type and place it in a collection
try:
table_taxi_obj = gpudb.GPUdbTable(
_type=taxi_columns,
name=table_taxi,
options=collection_option_object,
use_multihead_io=True,
multihead_ingest_batch_size=1000
)
print "Taxi table object successfully created"
except gpudb.GPUdbException as e:
print "Taxi table object creation failure: {}".format(str(e))
print "n"
print "INSERTING DATA"
print "--------------"
print
# Insert records from a CSV File into the Taxi table
print "Inserting records into the Taxi table via CSV..."
print
taxi_data = csv.reader(open('/tmp/data/taxi_trip_data.csv'))
taxi_data.next()
taxi_records = []
for record in taxi_data:
record_data = []
record_data.append(long(record))
record_data.append(long(record))
record_data.append(record)
record_data.append(long(record))
record_data.append(long(record))
record_data.append(int(record))
record_data.append(float(record))
record_data.append(float(record))
record_data.append(float(record))
record_data.append(float(record))
record_data.append(float(record))
taxi_records.append(record_data)
table_taxi_obj.insert_records(taxi_records)
# Flush any records at the end that is smaller than batch size
table_taxi_obj.flush_data_to_server()
print "Number of records inserted into the Taxi table: {}".format(
table_taxi_obj.size()
)
Note the difference between serial and multi-head ingest is only passing of use_multihead_io and multihead_ingest_batchsize options to GPUdbTable constructor and calling of the flush_data_to_server(). The rest of the code is identical between serial and multi-head ingest.
table_taxi_obj = gpudb.GPUdbTable(
_type=taxi_columns,
name=table_taxi,
options=collection_option_object,
use_multihead_io=True,
multihead_ingest_batch_size=1000
)
…
table_taxi_obj.flush_data_to_server()
A single flag and a flush call is all that is needed from the application to take advantage of Kinetica's parallel ingest. There is no need to be aware of how many nodes are in the cluster, where they are, or how the data is distributed across them! Best of all, this capability is widely available to developers via real-time data streaming tools in Kinetica's native Python, Java, and C++ APIs, and its ODBC and JDBC drivers. Kinetica's connector for real-time data streaming Kafka queues also uses this capability.
Simultaneous Read and Write
In addition to high-throughput parallel ingest, Kinetica enables high-performance simultaneous read on live, incoming data from real-time data streaming sources. As for design patterns for real-time streaming data analytics, Kinetica stores its data in a columnar fashion. That is, each column is stored independently from one another, enabling faster scans and projections.
In addition to columnar storage, Kinetica has designed smart underlying data structures that allow write and read operations to simultaneously access the same row's data without blocking each other. In many cases, these smart data structures can read from memory without touching the disk's persistent data for the fastest reads possible. From a developer's perspective, there is no need to wrap read and write operations in separate transactions. Each one is atomic unto itself.
High-throughput streaming ingest and simultaneous high-performance query, the two pillars of active analytics, result in a supercharged analytics data platform unlike any other. Thus, Kinetica enables the enterprise to tackle the toughest streaming use cases, delivering new insights with an elegant and user-friendly platform.
See the difference for yourself! Get started with Kinetica today by signing up for a free trial or contact us to learn more.
Dipti Joshi is director of product management at Kinetica.