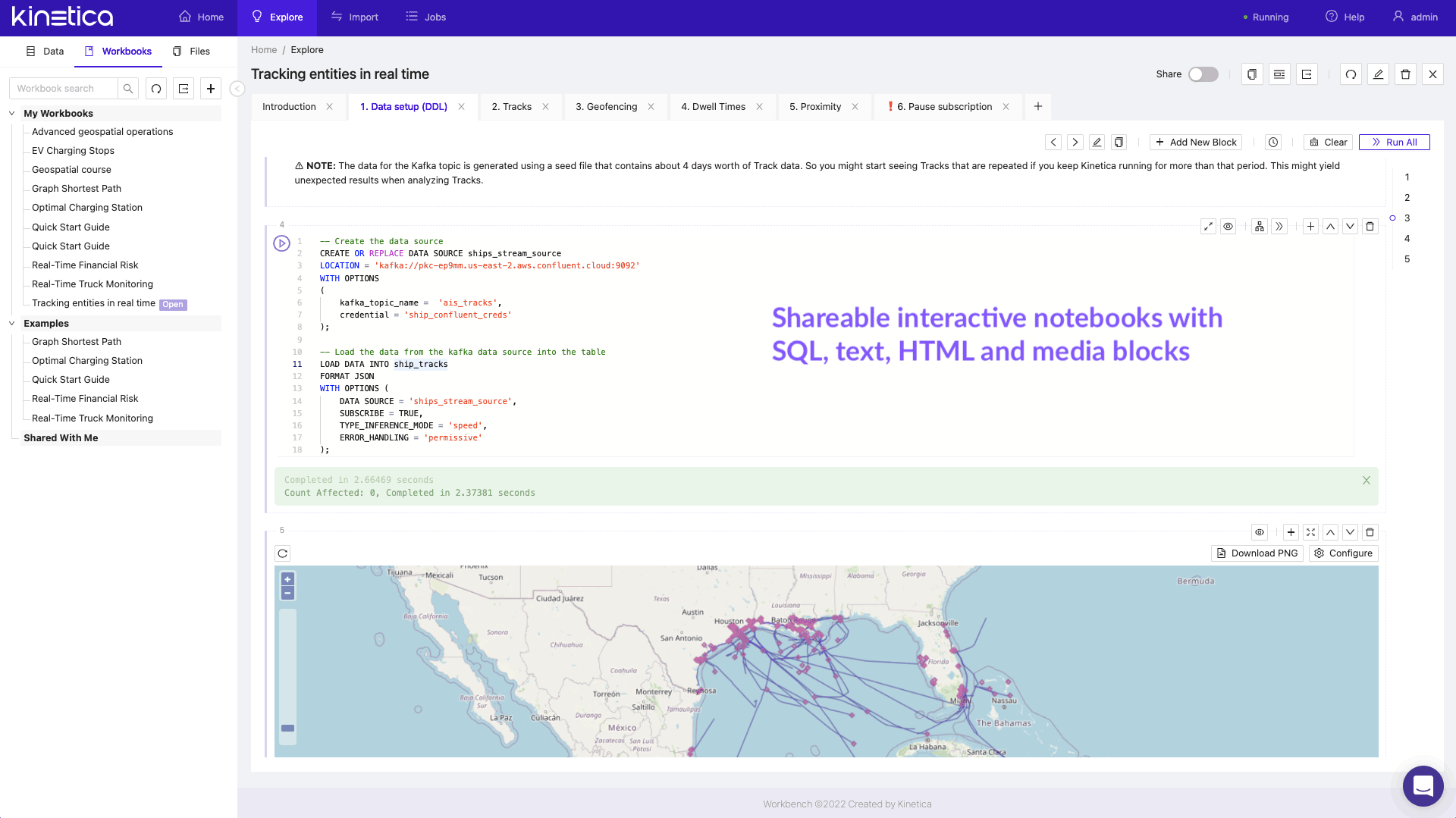
Generative AI | OLAP | Time Series analytics | Graph analytics | Spatial analytics
Accelerate your AI and analytics. Kinetica harnesses real-time data and the power of GPUs for lightning-fast insights.
The worlds biggest organizations trust us to solve their hardest problems
Why Kinetica
Elevate your Generative AI stack with real-time, operational data.
Real-time
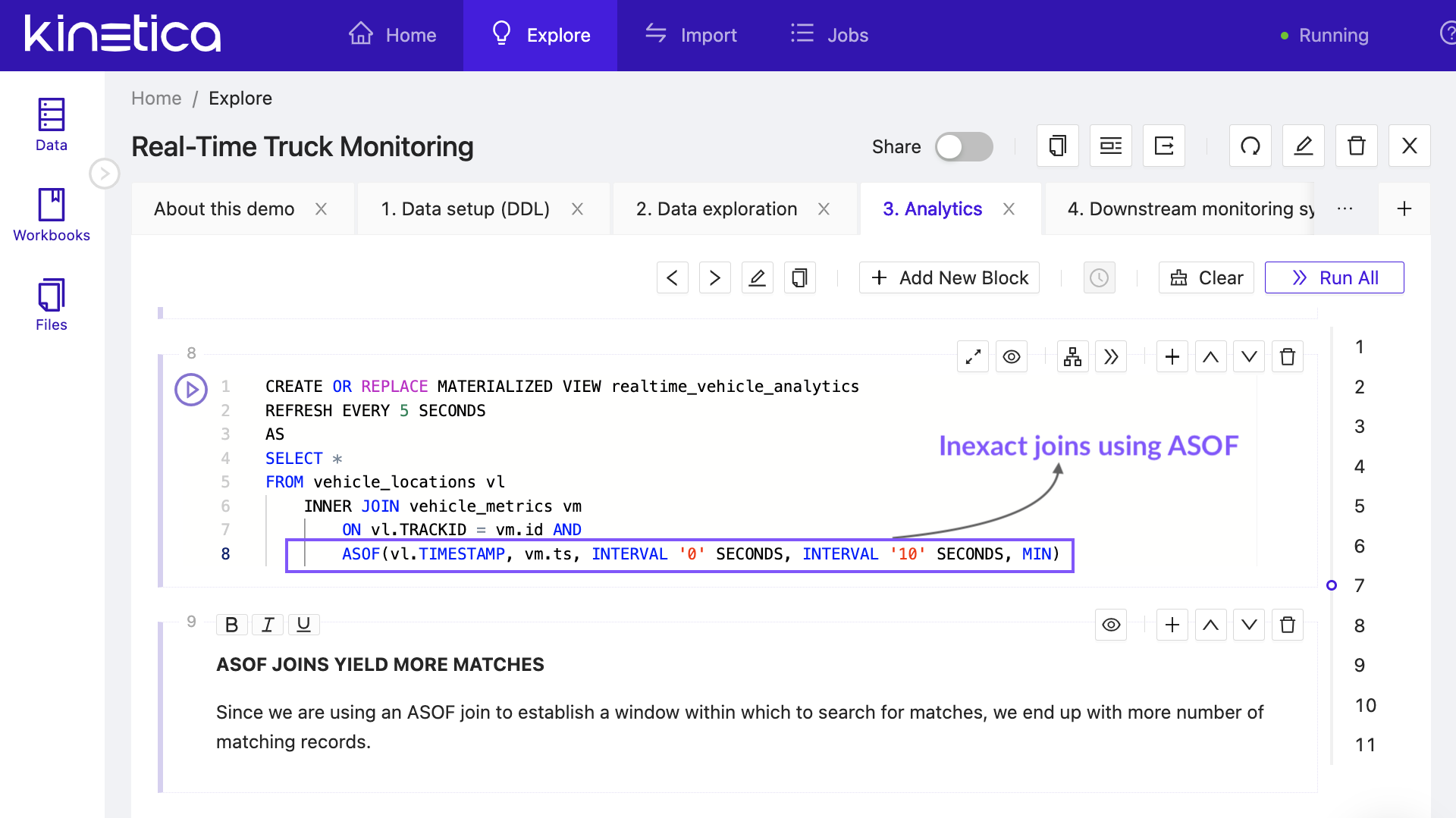
Ingest high volume data streams and execute queries simultaneously without any performance hit.
GPU accelerated
Harness the massive parallelization offered by GPUs to execute complex analytical and vector search queries in sub-seconds.
Generative AI
Unlock operational data for your LLMs using native semantic context object, real-time vector search and LangChain compatible plugins.
Everything you’d expect in an enterprise database
Write Queries in SQL
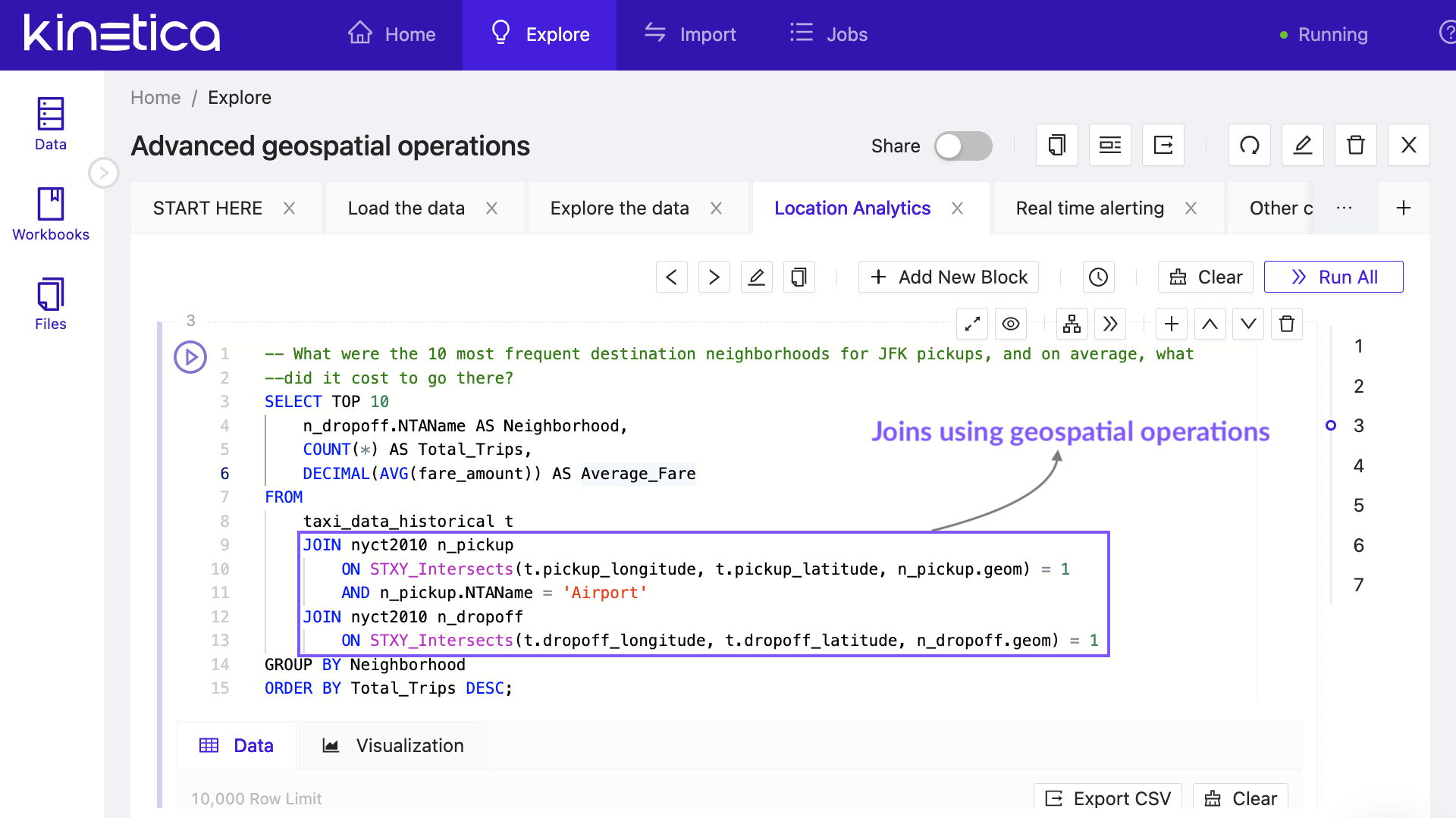
Kinetica is ANSI SQL compliant, making temporal and spatial analytics easy to use. SQL Query Support »
Flexible Cloud Deployment Options
Multiple deployment options across AWS, Azure, as a managed service or self-managed
Horizontal Scale Out
Work with petabytes of data at speed with Kinetica’s memory-first, fully distributed architecture.
Ingest/Egress Universal Formats
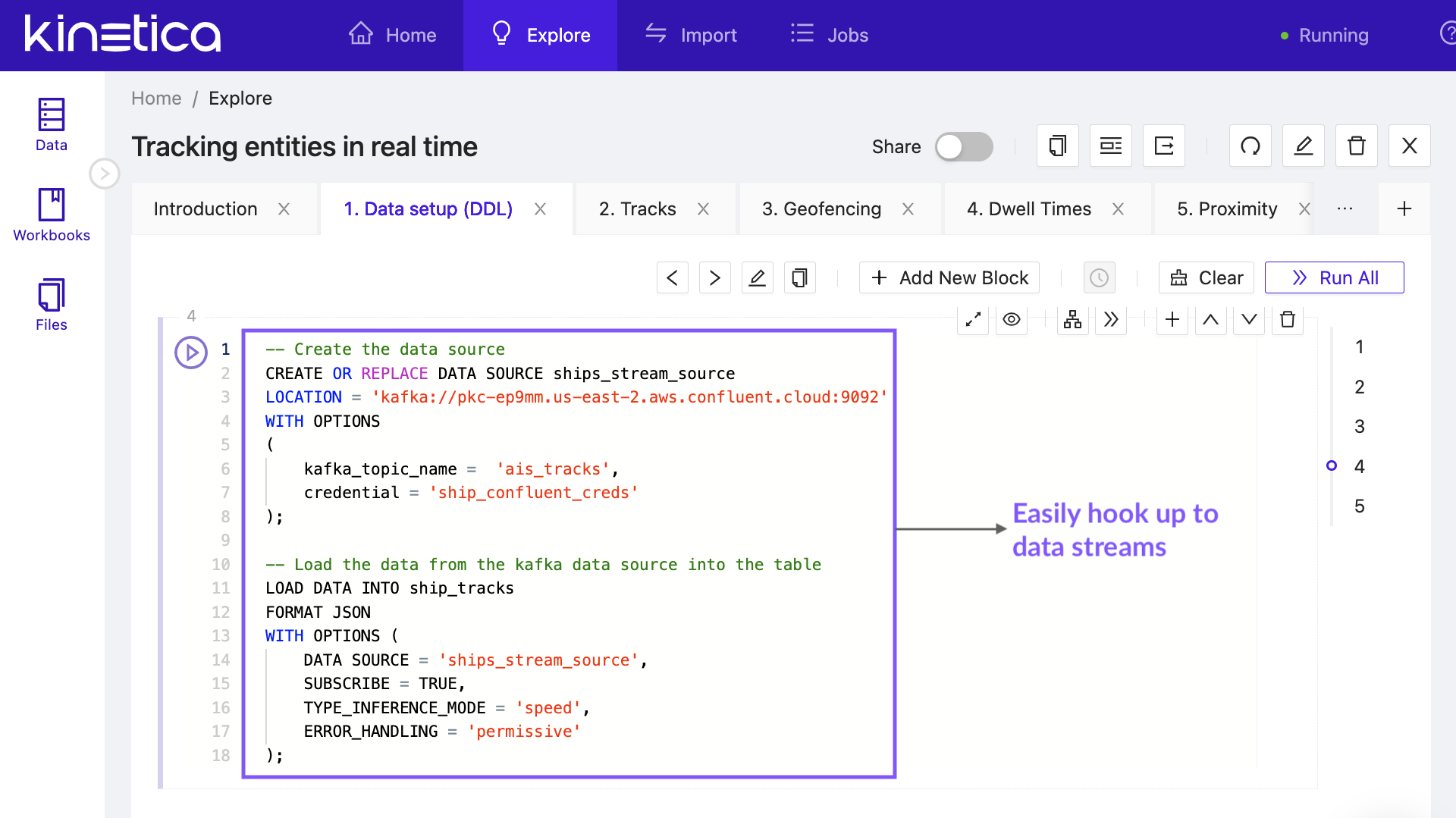
Set up continuous data pipelines with Kafka using a simple line of SQL. Or ingest/egress data from, and into, common data formats, including SQL, CSV, Avro, JSON, Parquet and ESRI shapefiles.Loading Data »
Cell-Level Security
Define dynamic obfuscation, redaction, and access rules down to the column level. Kinetica works with industry standard external authentication and identity systems like LDAP, Active Directory and Kerberos. Security »
REST & Native API's
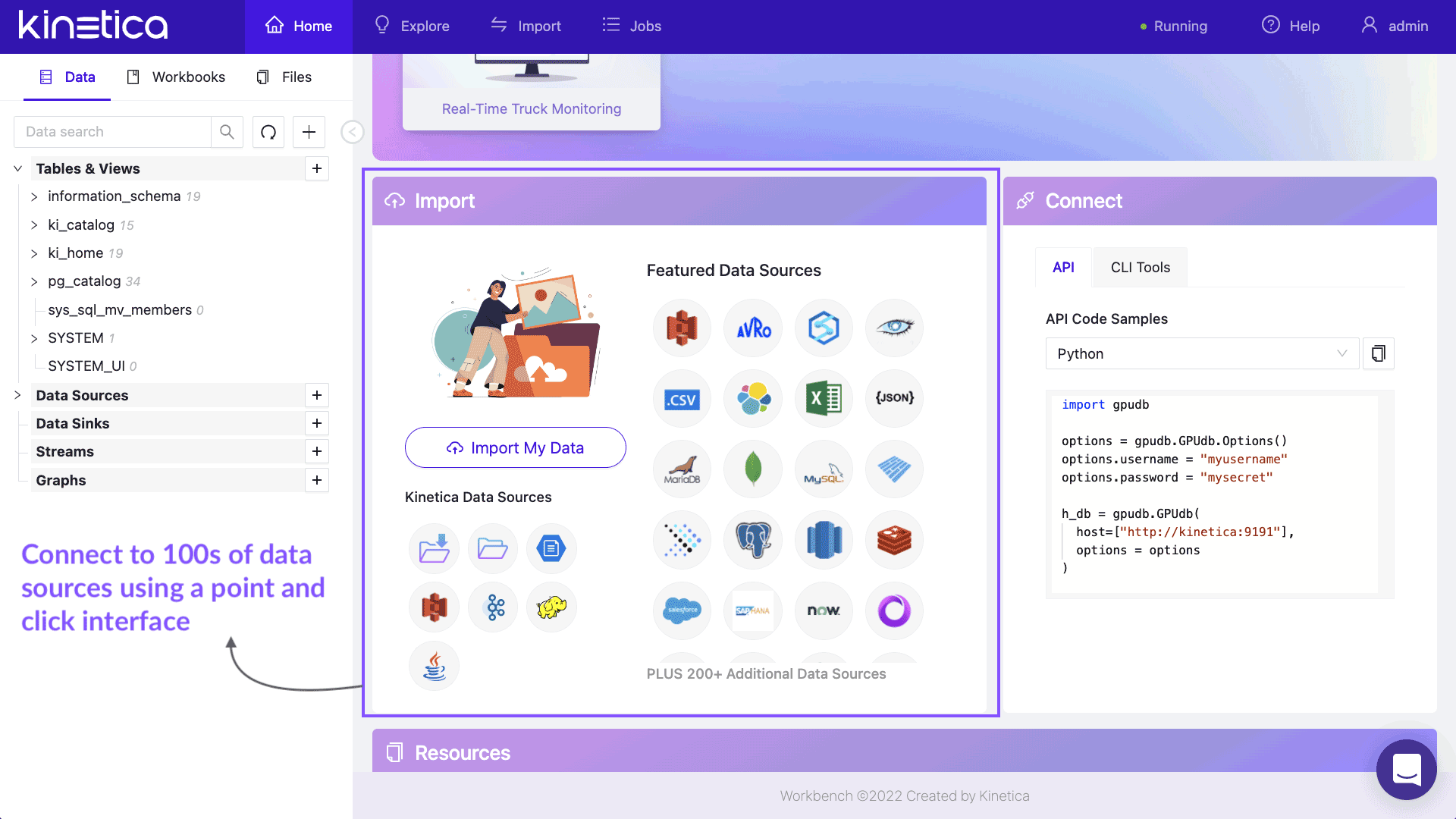
Data Scientists and Developers can develop sophisticated applications with REST and Native APIs. Language specific APIs are available for C++, C#, Java, Javascript, NodeJS & Python. API Documentation »
Postgres Compatible
Kinetica connects to a wide range of popular BI tools such as Tableau, Spotfire, PowerBI, ESRI, DBeaver and Grafana for real-time analytics with Postgres Wireline compatibility, or through the ODBC/JDBC connector.
High Availabilty
Kinetica offers node and process failover for in-cluster resiliency, and multiple clusters may be grouped in a ring resiliency to spread data and ensure eventual consistency. High Availability »
A Range of Industries Use Kinetica
Sensor and machine data is proliferating and creating new opportunities across many industries.
As sensor data grows more complex, legacy data infrastructure struggles to keep pace. A new set of design patterns to unlock maximum value. Get this complimentary report from MIT Technology Review
The best way to appreciate the possibilities that Kinetica brings to high-performance real-time analytics is to see it in action.
Contact us, and we’ll give you a tour of Kinetica. We can also help you get started using it with your own data, your own schemas and your own queries.